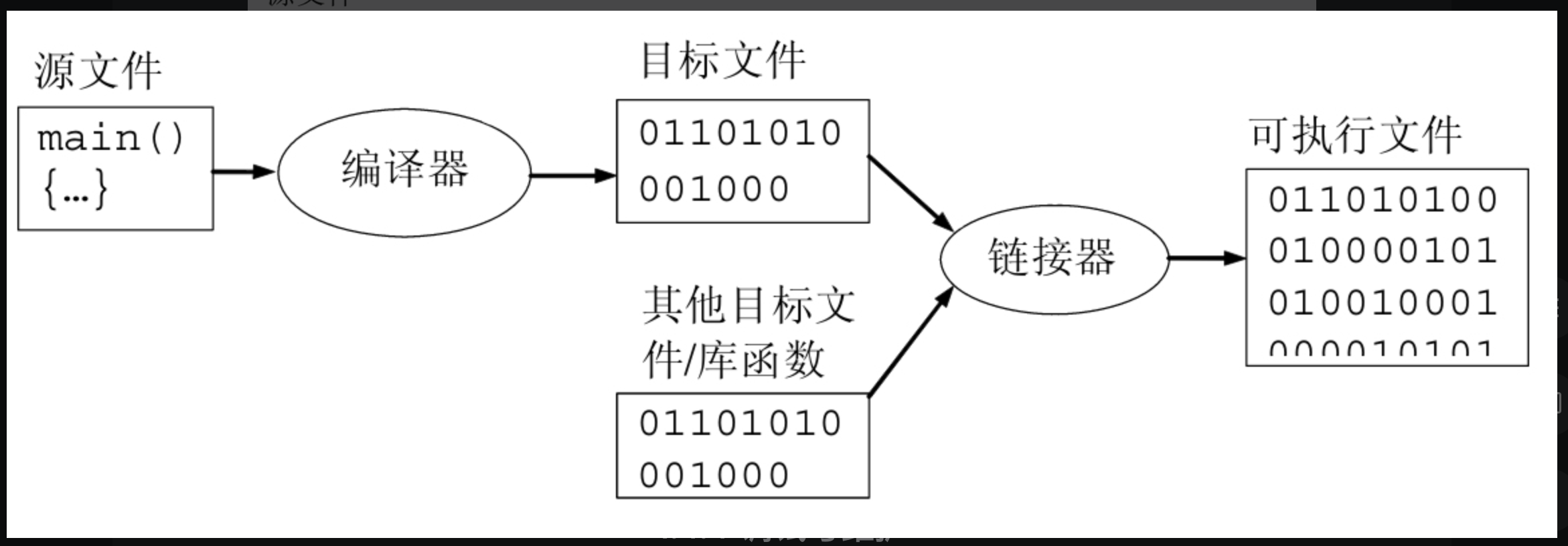
准备考试的记录罢了。
快速幂
1
2
3
4
5
6
7
8
9
long long powerOfMod ( long long base , long long power , long long mod ){ //快速幂
long long res = 1 ;
while ( power ){
if ( power % 2 == 1 ) res = ( res % mod * base ) % mod ;
base = ( base % mod ) * base % mod ;
power /= 2 ;
}
return res ;
}
质数判断
1
2
3
4
5
6
7
8
9
bool isPrime ( long long what ){
srand ( time ( NULL ));
for ( int r = 0 ; r < 10 ; ++ r ){ //多跑几个随机数以提高正确率
long long w = rand () % ( what - 2 ) + 2 ;
if ( powerOfMod ( w , what - 1 , what ) != 1 ){ return false ;} //费马小定理判断质数
}
return true ;
}
//对于不够大的数,比如int以内的,不如除法快
单源最短路径-Dijkstra
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
//洛谷P4779 单源最短路径 Dijkstra
//注意该算法要求图中不存在负权边。
//存储"边"来防止MLE--链式前向星
//用优先队列来减少复杂度避免TLE(堆优化)
#include<iostream>
#include<cmath>
#include<queue>
#define maxnum 2147483647
using namespace std ;
struct edge { //存储边的信息
int to , next , distent ;
};
struct edge edge [ 200005 ];
int head [ 100005 ] = { 0 };
int p = 0 ;
struct node { //存储节点的信息
int ans , id ; //ans表示到源点距离,id表示这个点的编号
//ans用在哪里?用在priority_queue中堆的维护上
bool operator < ( const node & x ) const //重载运算符
{
return ans > x . ans ;
}
//operator<()实际上成为了一个成员函数
//比如在运行到node1<node2时,发现<左边是node类,则...
//...会调用node1.operator<(node2),于是实际上比较了node1.ans和node2.ans
//而且换成大于号,因为priority_queue是大的在顶,我们希望小的在顶
};
priority_queue < node > q ; //定义一个优先队列
int dis [ 100005 ]; //记录到源点的最近距离
bool ok [ 100005 ]; //记录是否已找到到该点的最短路径
int main (){
int n , m , s ; //n个点,m条有向非负边,s是源点,计算s到任意点的最短距离,规定s=1
for ( int i = 0 ; i < 100005 ; ++ i ) { dis [ i ] = maxnum ; ok [ i ] = 0 ;}
cin >> n >> m >> s ;
for ( int i = 1 ; i <= m ; ++ i ){
int u , v , w ;
cin >> u >> v >> w ;
++ p ;
edge [ p ]. to = v ; //u点有一个连到v点的线
edge [ p ]. next = head [ u ]; //子节点的兄弟存入next
head [ u ] = p ; //u点的一个子节点存在p
edge [ p ]. distent = w ; //距离是w
//next指的是遍历时的下一条边,head指的是遍历时的第一条边
}
dis [ s ] = 0 ;
int u ;
q . push (( node ){ 0 , s }); //插入源点
while ( ! q . empty ()){
node tmp = q . top (); q . pop (); u = tmp . id ; //弹出堆顶给tmp
if ( ! ok [ u ]){ //如果堆顶还没有找过
ok [ u ] = 1 ; //那么现在它被找过了
for ( int i = head [ u ]; i ; i = edge [ i ]. next ){ //遍历从它出发的边
int v = edge [ i ]. to ;
if ( dis [ v ] > dis [ u ] + edge [ i ]. distent ){ //修正dis[v]的值
dis [ v ] = dis [ u ] + edge [ i ]. distent ;
if ( ! ok [ v ]){ q . push (( node ){ dis [ v ], v });} //如果他们也是没找过的,则放入堆中
}
}
}
}
for ( int i = 1 ; i <= n ; ++ i ){
cout << dis [ i ] << " " ;
}
return 0 ;
}
一种优雅的输入方式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
#include<iostream>
using namespace std ;
int main (){
cout << "输入这组数最大可能的个数" << endl ;
int max ;
cin >> max ;
int * a = new int [ max + 1 ];
cout << "输入一组数,用空格隔开,以.结束" << endl ;
int tmp , k = 0 ;
char c ;
while (( cin >> tmp ). get ( c )){ //这行如同魔法,实现了读取整数和读取分隔符
++ k ;
if ( k > max ) {
cout << "超出最大值" ;
break ;
}
a [ k ] = tmp ;
if ( c == '.' ) break ;
}
......
return 0 ;
}
语法syntax 语义semantics
冯·诺依曼体系:
1)计算机的硬件由5大部分组成,即运算器、控制器、存储器、输入设备和输出设备
运算器和控制器通常集成在CPU上
运算器由算术逻辑单元(ALU)和寄存器组成。ALU完成相应的运算,寄存器用来暂存参加运算的数据和中间结果。
2)数据的存储与运算采用二进制表示。每台计算机能完成的指令集合称为这台计算机的指令系统或机器语言。
控制器由程序计数器(PC)、指令寄存器(IR)、指令译码器(ID)、时序控制电路及微操作控制电路等组成。
3)数据的存储与运算采用二进制表示。
每条机器语言的指令一般都包括操作码和操作数两个部分。操作码指出了运算的种类,如加、减、移位等。操作数指出参加运算的数据值或数据值的存储地址,如内存地址或寄存器的编号。
硬件直接实现,功能简单,编制复杂。
用汇编程序把符号化的语言翻译成机器语言。
汇编语言解决了机器语言的可读性的问题,但没有解决机器语言的可移植性的问题,且功能和机器语言一样基本。
独立于机器硬件环境的一种语言,因而有较好的可移植性。高级语言提供的功能也比机器语言强得多,编写程序更加容易。
程序是计算机完成某个任务所需要的指令集合。通常程序设计都是基于高级语言。
第一步是设想计算机如何一步一步地完成这个任务的,即将解决问题的过程分解成程序设计语言所能完成的一个个基本功能,这一阶段称为算法设计;第二步是用某种高级语言描述这个完成任务的过程,这一阶段称为编码;第三步是将高级语言写的程序翻译成硬件认识的机器语言,这个阶段称为编译与链接;第四步是检验编好的程序是否正确完成了给定的任务,这一阶段称为调试。
算法必须具有以下3个特点。
(1)表述清楚、明确,无二义性。
(2)有效性,即每一个步骤都切实可行。
(3)有限性,即可在有限步骤后得到结果。
流程图被另一种称为N-S的图所代替。
另一种表示算法的工具称为伪代码。伪代码是介于自然语言和程序设计语言之间的一种表示方法。通常用程序设计语言中的控制结构表示算法的流程,用自然语言表示其中的一些操作。
编码就是将算法用具体的程序设计语言的语句表达出来
在高级语言和机器语言之间执行这种翻译任务的程序叫作编译器。
与其相关的是解释器,效果是逐句进行,且不保存目标代码。如python和matlab。
找出并改正这种逻辑错误的过程称为调试(debug),它是程序设计过程中一个重要的环节。
一个C++程序由注释、编译预处理和主程序组成。主程序由一组函数组成。每个程序至少有一个函数,这个函数的名字为main。
在C++语言中,注释是从//开始到本行结束。在C++程序中也可以用C语言风格的注释,即在/*与*/之间所有的文字都是注释,可以是连续的几行。
以#开头,常用的是库包含 。#include命令的意思就是把库的头文件插入到现在正在编写的程序中。用<>包含的是C++系统提供的标准库,预编译器会去标准库目录找;用“”包含的是个人库,预编译器会去用户目录找,找不到再去标准库找。
还有一个是宏定义 ,如#define SUM(a,b,c) (a+b+c),编译时会直接替换公式再计算(注意不是先算再代入)
为避免不同库中的名字发生重名,在引用库中实体时需要给出名字空间的限定。C++标准库的实体都定义在名字空间std中。
为了避免繁琐,可以用**using namespace std;**来省去比如std::cout中的std::部分。其中using namespace 也可以用于声明别的名字空间。
如果用双引号则会先去用户目录找
函数int main() 表示main函数没有输入值,其输出值是一个整型。函数最后一个语句是return 0,表示把0作为函数的执行结果值。一般情况下,main函数的执行结果都是直接显示在显示器上,没有其他执行结果。但C++程序员习惯上将main函数设计成返回一个整型值。当执行正常结束时返回0,非正常时返回其他值。
cout<<x1<<x2<<x3;应如何理解?"<<"是一个运算符,它把x1的内容放入cout,得到的结果是一个新的cout,再与后面一步的<<x2进行计算。
1
类型名 变量名 1 = 初值 , 变量名 2 ( 初值 ), 变量名 3. .....;
初值有两种赋法,也可以不赋初值。若定义一个变量时没有为其赋初值,然后直接引用这个变量是很危险的,因为此时变量的值为一个随机值。
变量名,以及后面提到的常量名和函数名,统称为标识符。
C++语言中标识符的构成遵循以下规则。
(1)标识符必须以字母或下划线开头 。
(2)标识符中的其他字符必须是字母、数字或下划线,不得使用空格和其他特殊符号。
(3)标识符不可以是系统的保留字,如int、double、for、return等,保留字在C++语言中有特殊用途。
(4)C++语言中,标识符是区分大小写 的,即变量名中出现的大写和小写字母被看作是不同的字符,因此ABC、Abc和abc是3个不同的标识符。
(5)C++没有规定标识符的长度,但各个编译器都有自己的规定。
类型表示什么?内存空间的大小,能进行的运算类型,能存储的数据类型。sizeof()可获取数据所占的大小。
原码:一位符号位,剩下的直接表示
反码:一位符号位,剩下的正数直接表示,负数取反
进制表示:10进制直接写,8进制前面以0开头,16进制以0x开头,可直接输入,但是cout会自动转为10进制
整数在计算机内一般是用补码表示的。正整数的补码是它的二进制表示,负整数的补码是将它的绝对值的二进制表示按位取反后再加1 (怎么算回去?还是取反再加1,这与减1再取反的效果是一样的)。例如,若一个整数占16位,10在内存中被表示为0000000000001010,-10被表示为1111111111110110。(你会发现这样加两个二进制数,抛弃进位得的最高位,正好是0000000000000000,补码实乃为便利负数参与运算也)在整数的补码表示中,最高位是符号位。正数的符号位为0,负数的符号位为1。
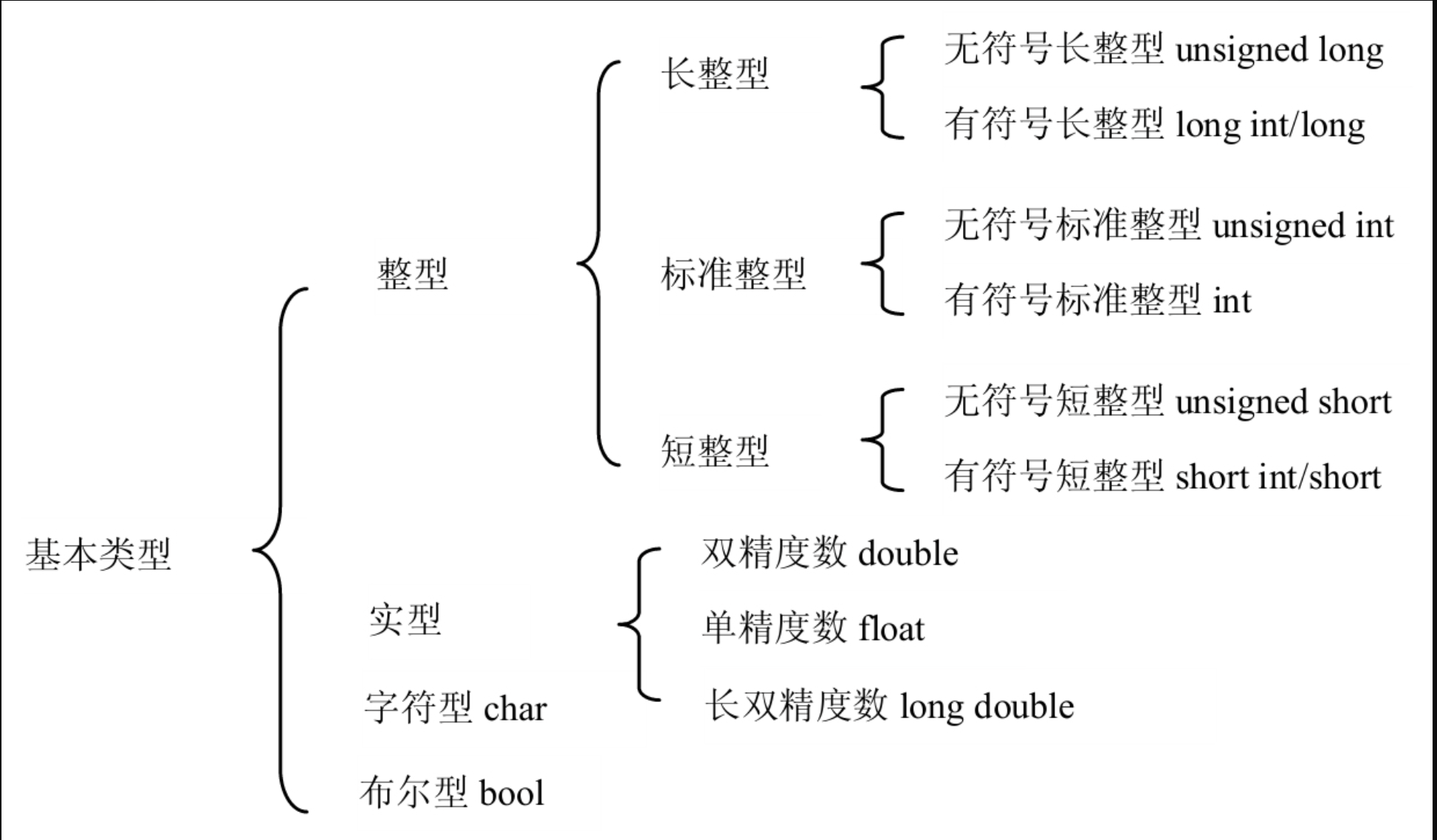
短整型和整型至少2字节,长整型至少4字节。但每个编译器可在此基础上加以扩展。
类型
类型名
在 Visual C++中占用的空间
表示范围
基本整型
int
4 字节
$-2^{31}∼2^{31}-1$
短整型
short [int]
2 字节
$-2^{15}∼2^{15}-1$
长整型
long [int]
4 字节
$-2^{31}∼2^{31}-1$
无符号基本整型
unsigned [int]
4 字节
$0∼2^{32}-1$
无符号短整型
unsigned short [int]
2 字节
$0∼2^{32}-1$
无符号长整型
unsigned long [int]
4 字节
$0∼2^{32}-1$
溢出 的例子:16位短整型,0111111111111111+1=1000000000000000,故32767+1=-32768,但程序不会报错。
1
2
3
4
5
6
7
8
9
short x = 32767 ;
short y = x + 1 ; //y=-32768
short q =- 1 ;
unsigned short z = q ; //z=65535,这个直接赋值,导致错误
int s = q ; //s=-1
unsigned int a = q ; //a=4294967295 带符号整数,扩展长度是扩展符号位
unsigned int o = s ; //o=65535 而unsigned扩展长时候是0扩展
float p = x ; //p=32767,这个会自动转换类型
cout << x + 1 ; //输出32768,因为1作为常量默认是int型
浮点数的存储方式:$flt=(−1)^{sign}×mantissa×2^{exponent},mantissa=1+f$。
f存0011101,ex存4,符号存0,则得到$1.0011101[2]\times 2^4$,4次幂相当于把小数点移过去4格(这就是“浮点”的意思,就是说点是浮动的),得到10011.101,转化为10进制得到19.625
float至少必须保证有十进制6位有效数字。double和long double必须保证有10位有效数字。
float是1符号+8指数+23底数,double是1+11+52。底数存的位数如果超出则只能截断,底数为1.x,其中1.是默认的。浮点无法准确存储数据,如果想要精确则尽量避免浮点运算。其中指数是移码存储,移动127,以便于比大小。
怎么算精度?尾数就是精度,3字节尾数则23位2进制(还有一位是符号),$2^{23}=8388608$故为7位。如果一个实数的位数超过尾数所能表示的范围,有效位以外的数字将被舍去,这样就会产生一些误差。例如,将9876543.21存放在float类型的变量x中,那么x中的值为9876540。计算机不能精确表示实型数。
ASCII编码用8位二进制数表示一个字符。即每个字符对应一个0到255之间的整数。
0~9,a~z,A~Z分别是连续的。
char占一字节,存ACSII,ACSII在运算时被当作整数处理。
空格是32,0是48,A是65,a是97。反斜杠表示转义字符,详见后面字符常量的介绍。
占一字节,true为1,false为0。布尔型的数据不可以直接输入输出。如果直接输出一个布尔型的变量,将会显示0或1。
需要自己定义。
1
2
3
4
enum 枚举类型名 { 元素表 };
enum weekdayT { Sunday , Monday , Tuesday , Wednesday , Thursday , Friday , Saturday }; //表示 Sunday=0,Monday=1...
enum weekdayT { Sunday = 1 , Monday , Tuesday , Wednesday , Thursday , Friday , Saturday }; //表示 Sunday=1,Monday=2...
enum weekdayT { Sunday , Monday , Tuesday = 5 , Wednesday , Thursday , Friday , Saturday }; //表示 Sunday=0,Monday=1,Tuesday=5,Wednesday=6...
一旦定义了枚举类型,就可以定义枚举类型的变量
1
2
3
4
5
枚举类型名 变量表 ;
weekdayT weekday ; //比如这样定义一个weekdayT型变量weekday
weekday = Sunday ; //可以这么赋值
while ( weekday <= Saturday ) //可以这么比较
weekday = 3 ; //但不可以这么赋值
事实上,布尔类型就是C++事先定义好的一个枚举类型。
不能直接输入输出。
C++提供了一个typedef指令,用这个指令可以重新命名一个已有的类型名。
1
2
3
typedef int integer
int a ; //仍旧可以这样定义变量
integer b ; //也可以这么定义变量了
用sizeof()得到占用空间(字节)的大小,若用于表达式则输出其结果所占的空间大小。
sizeof('a'+15),a是char是1B,15是int是4B,输出4B。sizeof(a),a是一个数组名的话,会输出这个数组的总大小。
如果你需要计算机把一个整数看成是长整型时,可以在这个整数后面加一个"l"(是小写L不是大写i)或"L"。如100L表示把这个100看成是长整型。
十进制直接写。八进制常量以0开头。十六进制数以0x开头。
科学计数法:字母e或E之前必须有数字;e后面必须是整数,不能有小数;e前面可以是小数。
C++中,实型常量都被作为double型处理。如果要将一个实型常量作为float类型的数据,可在数值后面加上字母F。例,1.23F或1.2e3F。
要用单引号括起来。有的是“非打印字符”,用到转义序列,如换行('\n')、tab('\t')。
当编译器看见反斜杠字符时,会认为是转义序列开始了。如果要表示反斜杠本身,必须在一对单引号中用两个连续的反斜杠,如'\\'。同样,当单引号被用作为字符常量时,必须在前面加上一个反斜杠' \ ' ' (这最终表示的是一个单引号)。由于双引号作为字符串的开始和结束标记,因此,当双引号作为字符串的一部分时,也必须写成转义序列。
转义序列也可以出现在字符串常量中,比如'Hello \n World'。
反斜杠表示转义字符,有多种进制,\x20是16进制,\40是8进制(不用0开头即可),他们都表示空格。但是不能用/32,十进制不可。
只有true和false。且非0则是true,不论正负。且不能直接输入输出,如果直接输出则true为1,false为0
对于程序中一些有特殊意义常量,可以给它们取一个有意义的名字,便于读程序的程序员知道该常量的意义。有名字的常量称为符号常量。
1
2
3
#define 符号常量名 字符串
#define PI 3.14159 //像这么定义,这个不会分配内存空间
S = PI * r * r ; //像这么用
因为C语言对“宏”的处理只是简单的替换,如果定义#define PI 3+0.14159,在具体运算中不会先计算加法,而是先代入,则$PIr r$就会变成$3+0.14r r$,计算顺序与预期不符。
1
2
3
4
const 类型名 符号常量名 = 表达式
const double PI = 3.14159 ; //像这么定义,这个会分配内存空间
int n = 5 ;
const int N = n + 1 ; //也可以这么定义
符号常量名的命名规范与变量相同。但通常变量名是用小写字母或大小写字母组成,而符号常量名通常全用大写字母。
当程序执行到输入语句时,会停下来等待用户的输入。此时用户可以输入数据,用回车(↙)结束。当有多个输入数据时,可以用空白字符(空格、制表符和回车)分隔。
1
2
3
4
5
int a , b ;
char str1 , str2 ;
cin >> a >> b ; //读入
cin . get ( str1 ); //读入字符的方式1
str2 = cin . get (); //读入字符的方式2
与>>操作略有不同,get函数可以接受任何字符,包括空格、Tab甚至回车。在get拿够了(比如程序是好几个get写一起)才会把回车理解为输入的结束。
cin>>在回车后才会从缓冲区拿值。
如果给cin读进去不符合数据类型的数据,那么它拿到的是看似随机的值。不过它会尽力去读,比如1.4它能为了符合数据类型去读成1和0.4(虽然也不是符合预期的),但是给int读一个char它就真无能为力了。
1
2
3
4
5
6
7
8
int num ;
cin >> num ;
while ( cin . fail ()) { //返回cin的状态
cin . clear (); //清除cin的错误状态
cin . ignore (); //忽略缓冲区的内容,直到EOF
cout << "输入错误,请重新输入" << endl ;
cin >> num ; //重新输入
}
上面是一种更安全的输入方式
!此外,如果给一个int型用cin输入一个超大的数字,则会直接给2^31-1,不溢出
可以一次性输出很多变量的值,也可以输出表达式的值。另外,endl表示输出一个换行符。
1
2
3
4
cout << "x1=" << x1 << " x2=" << x2 << "x1+x2=" << x1 + x2 << endl ;
cout << fixed << setprecision ( 3 ) << pi << endl ; //保留三位小数,自动四舍五入,注意要用<iomanip>库
printf ( "%.2f" , pi ); //简单好用!也会自动四舍五入
cout . put ( ch ); //直接输出字符,且这个方式不能输出字符串
其中+、-、*、/的含义与数学中完全相同。%运算是取两个整数相除后的余数。
乘、除、取模运算的优先级高于加减运算。优先级相同时,从左计算到右。
只允许圆括号改变优先级,别的括号另有用处。
运算结果的类型与运算数类型相同 。在进行不同类型的数据运算之前,系统会自动将运算数转换成同一类型,再进行运算。这种转换称为自动类型转换 。转换的总原则是非标准类型转换成标准类型,占用空间少的向占用空间多的靠拢,数值范围小的向数值范围大的靠拢。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
#include<iostream>
using namespace std ;
int main (){
int INT = 1 ;
unsigned UNS = 2 ;
short SHT = 3 ;
char CHR = 'a' ;
long long LLO = 1000 ;
long LON = 100 ;
float FLT = 1.1 ;
double DBL = 1.111111 ;
cout << typeid ( UNS ). name () << "=" << typeid ( INT + UNS ). name () << endl ; //j=j
cout << typeid ( LON ). name () << "=" << typeid ( UNS + LON ). name () << endl ; //l=l
cout << typeid ( LLO ). name () << "=" << typeid ( LON + LLO ). name () << endl ; //x=x
cout << typeid ( INT ). name () << "=" << typeid ( INT + SHT ). name () << endl ; //i=i
cout << typeid ( FLT ). name () << "=" << typeid ( INT + FLT ). name () << endl ; //f=f
cout << typeid ( DBL ). name () << "=" << typeid ( DBL + LLO ). name () << endl ; //d=d
cout << typeid ( FLT ). name () << "=" << typeid ( FLT + LLO ). name () << endl ; //f=f
cout << typeid ( CHR ). name () << typeid ( SHT ). name () << typeid ( SHT + CHR ). name () << endl ; //csi !!
}
char , short -> int -> unsigned -> long -> long long -> float -> double
• 实型转换成整型时,舍弃小数部分。
• 整型转换成实型时,数值不变,但表示成实数形式。如1被转换为1.0。
• 字符型转换成整型时,不同的编译器有不同的处理方法;有些编译器是将字符的内码看成无符号数,即0~255之间的一个值。另一些编译器是将字符的内码看成有符号数,即-128~127之间的一个值。
• 布尔型转换成整型时,true为1,false为0。
• 整型转换成字符型时,直接取整型数据的最低8位。
9.0/4.0=2.25; 9/4.0=2.25; 9.0/4=2.25; 9/4=2(不是四舍五入,是抹去小数)
怎么输出正确的值呢?使用强制类型转换。写成double(9)/4或者9/double(4)。
一般情况下,尽可能避免使用强制类型转换,它只是用于解决非常特殊的问题的手段。
强制类型转换的性质有4种:静态转换(static_cast)、重解释转换(reinterpret_cast)、常量转换(const_cast)和动态转换(dynamic_cast)。
1
2
3
4
5
char ch ;
int d = 10 ;
ch = d ; //这样写,程序会自己执行自动类型转换
ch = static_cast < char > ( d ); //这样写,明确指明此处有一个转换。
//静态转换告诉程序的读者和编译器:我们知道并且不关心潜在的损失。
1
#include <cmath> //用这行来引入除了+-\*/%的数学函数
函数类型
cmath 中对应的函数
绝对值函数
int abs(int x)
double fabs(double x )
e^(x)
double exp( double x)
x^(y)
double pow(double x, double y)
sqrt(x)
double sqrt(double x)
ln x
double log( double x)
lg x
double log10 (double x)
三角函数
double sin( double x)
double cos( double x)
double tan( double x )
反三角函数
double asin(double x )
double acos(double x)
double atan(double x )
注意pow和fabs
特别是pow和abs要记得引入cmath!
-5/2的结果如何?旧版-2、-3的都有,C++11新标准则规定一律向0取整(即直接去掉小数部分)。
(-9)%(-4)的结果是多少?C++11规定,m%(-n)= m%n,(-m)%n= -(m%n)。不允许(-m)%(-n)。
在C++中,能出现在赋值运算符右边的表达式称为右值(rvalue),能出现在赋值运算符左边的表达式称为左值(lvalue)。左值必须有一块可以保存信息的内存空间。而右值是用完即扔的信息。当表达式的结果类型和变量类型不一致时,同其他的运算一样会发生自动类型转换。系统会将右边的表达式的结果转换成左边的变量的类型,再赋给左边的变量。
1
2
3
int total ;
total = 0 ; // 这是一个赋值语句
cout << ( total = 0 ); // 这将输出“0”
表达式(x = 6) + (y = 7)等价于分别将x和y的值设为6和7,并将x和y相加,整个表达式的值为13。在C++中,=的优先级比+低,所以这里的圆括号是必需的。将赋值表达式作为更大的表达式的一部分称为赋值嵌套 。
赋值运算符是右结合的。
1
2
3
4
n1 = n2 = n3 = 0 ;
n1 = ( n2 = ( n3 = 0 )); // 实际上执行的是这样
int i ; double d ;
d = i = 1.5 ; // 这行的效果:先将1.5截去小数部分赋给i,因此i得到值1;表达式i=1.5的结果是变量i,也就是将整型变量i的值赋给d,即将整数1赋给了d,而不是浮点数1.5,该值赋给d时再引发第二次类型转换,所以最终赋给d的值是1.0。
在赋值中,二元运算符与=结合的运算符称为复合赋值运算符。
1
2
变量 = 变量 op 表达式 ;
变量 op = 表达式 ; // 上一行为了简便可以写成这样
赋值运算符(包括复合赋值运算符,如+=、*=等)的优先级比算术运算符低。
1
2
3
4
5
6
7
8
x = x + 1 ;
x += 1 ;
x ++ ; // 可以这么写
++ x ; // 也可以这么写
x -- ; // 或者这么写。当++作为前缀时,表示先将对应的变量值增加1,然后参加整个表达式的运算;当++作为后缀时,将此变量值加1,但参加整个表达式运算的是变量原先的值。
//简而言之,++x先运算再赋值,x++先赋值再运算
y = ++ x ; // 这个结束后y=x=原来的x+1
y = x ++ ; // 这个结束后y=原来的x,x=原来的x+1
前缀操作所需的工作更少,只需加1或减1,并返回运算的结果即可;而后缀的++或--需要先保存变量原先的值,以便让它参加整个表达式的运算,然后变量值再加1。
略
分支程序设计必须具备两个功能:第一是如何区分各种情况,第二是如何根据不同的情况执行不同的语句。前者用关系表达式和逻辑表达式来实现。后者用两个控制语句来实现。
<(小于)、<=(小于等于)、>(大于)、>=(大于等于)、==(等于)、!=(不等于)
前四个的优先级高于后两个,算术运算符的优先级比关系运算符高,关系运算符的优先级比赋值运算高
(a = b) < 5表示先把变量b的值赋给a,再将变量a中的值和5进行比较。如果去掉这个表达式中的括号,那么表达式a = b < 5表示将关系表达式b < 5的运算结果存放在变量a中。
关系表达式会进行自动类型转换,将关系运算符两边的运算数转换成相同类型。
关系表达式的计算结果是布尔型的值:true和false。
!(逻辑非)、&&(逻辑与)和||(逻辑或)。 优先级为:!最高,&&次之,||最低。
0<x<10是不可以的,会先执行0<x的判断,然后拿true或false和10比。应该写成0<x &&x<10。
逻辑运算也会有自动类型转换,将0转为false,非0转为true。
为了提高计算效益,C++提出了一种短路求值 的计算方法。逻辑运算在能得到结果的时候,剩下的部分不再被计算。短路求值的一个好处是减少计算量,另一个好处是第一个条件能控制第二个条件的执行。在很多情况下,逻辑表达式的右运算数只有在第一部分满足某个条件时才有意义。
所以,在写逻辑表达式时,如果是执行“与”运算,最好将最有可能是false的判断放在左边,如果是执行“或”运算,最好将最有可能是true的判断放在左边。这样可以减少计算量,提高程序运行的效率。
1
( year % 4 = = 0 && year % 100 != 0 ) || year % 400 == 0 //判断闰年
但是注意不要在一个复杂逻辑表达式中执行赋值,有可能它被短路了导致赋值没赋上去。
另外,注意力放在短路的同时,还要注意到底是不是要输出,上下文看全一点
if的条件理应是一个关系表达式或逻辑表达式,但不管是什么类型的表达式实际上都能跑而不报错,C++认为当表达式值为0时表示false,非0则为true。
1
2
3
4
5
6
7
8
if ( 条件 ) 做什么 ; // 否则什么也不做
if ( 条件 ) 做什么 ;
else 做什么 ; // 只有一句话可以没有大括号
if ( 条件 ) {
做很多 ;
} else {
做很多 ; // 有多句话要大括号
}
注意,条件的后面没有分号!若写if (a > b); max = a;编译器会认为是2个独立的语句;其中第一个if语句的then子句是空语句,并且没有else子句。
此外,注意x==1,要写两个等号才表示判断,这个错误编译器不会报错。
多层嵌套的if语句的else可能存在归属的歧义,C++编译器采取一个简单的规则,即每个else子句是与在它之前最近的一个没有else子句的if语句配对的。
对于非常简单的分支情况,C++语言提供了另一个更加简练的用来表达条件执行的机制:?:运算符。
1
2
3
sth = ( 条件 ) ? 表达式 1 : 表达式 2 ; //当C++程序遇到 ?: 运算符时,首先测试条件。如果条件测试结果为true,则计算表达式1的值,并将它作为整个表达式的值。如果条件结果为false,则整个表达式的值为表达式2的值。算出来的值被赋给sth。
max = ( x > y ) ? x : y ; //简洁地求更大值
cout << ( flag ? "True" : "False" ) << endl ; // 简洁地输出bool变量(如果直接输出flag则会输出1或0,而非Ture和False)另注意,<<运算符的优先级比?:运算符的优先级高。
加在条件两边的括号从语法上讲是不需要的,但有很多C++程序员用它们来强调测试条件的边界。
多分支情况下适用
1
2
3
4
5
6
7
switch ( 控制表达式 ) {
case 常量表达式 1 : 语句 1 ;
case 常量表达式 2 : 语句 2 ; break ; //break语句的作用就是跳出switch语句。如果这里没有break关键字,它就会继续向下执行后继的case分支(不再检查是否满足对应的case),直到遇到break关键字或者是其后的所有分支执行完毕。若将break语句作为每个case子句的最后一个语句,可以使各个分支互不干扰。
...
case 常量表达式 n : 语句 n ;
default : 语句 n + 1 ; //default子句可以省略。当default子句被省略时,如果控制表达式找不到任何可匹配的case子句时,直接退出switch语句。
}
如果有多个分支执行的语句是相同的,则可以把这些分支写在一起,相同的操作只需写一遍。怎么实现呢?不要写操作也不要写break就是了。
switch关键字后括号中的条件量必须是整型 的数值变量或表达式,或者是能够被转换为整型的其他类型(字符类型或者枚举类型等)。 因为switch之后的条件量是整型,为了与之比较,所以case之后的常量 值也必须是整型。各个case分支的常量值不能相等。
case后面的表达式中包含变量会报错。
如果要各分支互不影响,记得break!记得break!
1
2
3
4
5
6
7
8
9
10
switch ( score ) {
case score >= 90 : cout << "A" ; break ;
case score >= 80 : cout << "B" ; break ;
default : cout << "C" ;
} // 这是没法执行的
switch ( score / 10 ) {
case 9 : cout << "A" ; break ;
case 8 : cout << "B" ; break ;
default : cout << "C" ;
} // 应该这么写
随机数生成器能随机生成0~RAND_MAX之间的整型数,包括0和RAND_MAX。RAND_MAX是一个符号常量,定义在库cstdlib中,它的值与编译器相关。在Visual C++中,它的值是32 767。生成随机数的函数是rand()。每次调用rand()都会得到一个0~RAND_MAX 的整数,而且这些值的出现是等概率的。输出1~n则用1+rand()%n。
库cstdlib 中有随机数生成函数。本次产生的随机数是生成下一个随机数时的输入。第一次产生随机数时的输入是C++指定的一个默认值(称为随机数的种子)。由于每次运行程序时给出的种子都是同一个值,产生的随机数自然也相同。C++提供了设置种子的函数srand,允许程序员在程序中设置随机数的种子。但如果程序员设置的种子是一个固定值,那么该程序每次执行得到的随机数序列还是相同的。把系统时间设为种子是一个很好的想法。time(NULL)就是取当前的系统时间。为了使用时钟,需要包含头文件ctime 。
用srand(time(NULL));来初始化随机数种子,然后再用rand()就好了。
略
1
2
3
for ( i = 0 ; i < n ; ++ i ) {
需要重复执行的语句们 ; //如果需要重复执行的语句只有一个,可以省略花括号。
}
执行顺序是赋初值,判断,运行语句块,循环变量加步长,判断,运行,加步长,判断……直到判断不成立,退出。
循环终止条件不一定是检查循环次数,可以是更复杂的关系表达式或逻辑表达式。
大多数编译器中,循环变量在循环结束时被销毁。
如果循环不需要任何初始化工作,则表达式1可以省略。如果循环前需要做多个初始化工作,可以将多个初始化工作组合成一个逗号表达式 ,作为表达式1。也可以把所有的初始化工作放在循环语句之前,此时表达式1为空。
逗号表达式按顺序运算到最后,逗号的优先级最低。如for(int i=0,j=5;i<j;i++,j--)像这样写是合法的。逗号表达式的值是最后一个基本表达式的值。
一个很优雅的求1加到100的式子:for(int i=1,s=0;1<=100;s+=i++); 太优雅了!
表达式2也不一定是关系表达式。它可以是逻辑表达式,甚至可以是算术表达式。当表达式2是算术表达式时,只要表达式的值为非0,就执行循环体,表达式的值为0时退出循环。
表达式3也是可以省略的。for(;;);就是一个最简单的死循环。
1
2
3
for ( int i = 1 ; i < 5 ; ++ i ){ 语句块 ;} //这个i在for退出后被销毁(成为无定义)
int j ;
for ( j = 1 ; j < 5 ; ++ j ){ 语句块 ;} //如果for里面不写int,那么就得在外面定义,且这个j在for退出后其内部的值仍旧保留
一个有趣的例子
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
#include <iostream>
int main (){
using namespace std ;
int i = 100 , j = 100 , k = 100 ;
cout <<& k << endl ;
for ( int i = 1 ; i < 5 ; ++ i ){ cout << "H" ;}
for ( j = 1 ; j < 5 ; j ++ ){ cout << "L" ;}
cout << endl ;
int * a ;
for ( int w = 1 ; w < 5 ; ++ w ){
int k ;
k = k + w ;
cout << k << "=" <<& k << " " ;
a =& k ;
}
cout << endl <<* a << "=" << a << endl ;
cout <<& k << endl ;
cout << i << " " << j << " " << k ;
return 0 ;
} /*输出如下
0x7ffeea2db640
HHHHLLLL
1=0x7ffeea2db628 3=0x7ffeea2db628 6=0x7ffeea2db628 10=0x7ffeea2db628
10=0x7ffeea2db628
0x7ffeea2db640
100 5 100 */
for循环的花括号内可以定义变量,这个变量的有效时间仅在这一个循环周期内。一个{}就是一个块,在{}块内定义的变量,只能在{}块内访问 。但是只是销毁了,内存中的东西没有被清除,有趣的是申请了同一个地址而且我没有给初值,于是乎,k增起来了。(尚待验证)
如果嵌套,每个for循环都要有一个自己的循环变量,以避免循环变量间的互相干扰。
范围for循环
1
for ( int i : { 1 , 9 , 6 , 8 , 3 }) // 该循环控制行遍历后面列表中的每一个值。第一个循环周期,i的值为1。第二个循环周期,i的值为9。以此类推,该循环一共执行了5个循环周期。
break语句除了跳出switch语句之外,也可以用于跳出当前的循环语句,执行循环后面的语句。
continue语句的作用是跳出当前循环周期,即跳过循环体中continue后面的语句,回到循环控制行。
注意区分break和continue。
注意一个break只能跳出一层。
根据某个条件成立与否来决定是否继续的循环称为基于哨兵的循环。
比如在输入的最后用一个哨兵来告知输入结束。
1
2
3
while ( 表达式 ){
语句块 ;
} //与for语句一样,当循环体只有一条简单语句构成时,C++编译器允许去掉加在循环体两边的花括号。
程序执行while语句时,先计算出表达式的值(表达式理应得到bool型,若不是则会自动转换,任何非0值都表示true)。如果是false,循环终止,并接着执行在整个while循环之后的语句;如果是true,整个循环体将被执行,而后又回到while语句的第一行,再次对条件进行检查。
注意1:第一个周期也参与检查,如果一开始测试结果便为false,则循环体根本不会被执行。
注意2:对条件的测试只在一个循环周期开始时进行;如果碰巧条件值在循环体的某处变为false,程序在整个周期完成之前都不会注意它。
1
2
3
do {
语句块 ;
} while ( 表达式 );
先执行循环体,然后判别条件表达式,如果条件表达式的值为true,继续执行循环体,否则退出循环。
和while的区别就是他先运行body再判断。
注意do后哪怕只有一句也要写大括号。
abs()是对整数取绝对值,fabs()是对浮点数取绝对值。
当一个循环中有一些操作必须在条件测试之前执行时,称为循环中途退出问题。
1
2
3
4
5
6
7
8
9
10
操作;
while ( 判断 ){
执行需要执行的语句 ;
操作;
}
while ( 1 ) {
操作 ;
if ( 判断不成立 ) break ;
执行需要执行的语句 ;
} // 这种写法不需要写两次“操作;”
注意枚举的效率,尽可能次数少,判定是否提前退出。
在求解过程的每一阶段都选取一个在该阶段看似最优的解,最后把每一阶段的结果合并起来形成一个全局解。该法并不是对所有问题都能得到最优解。
难度在于找到贪心标准
1、背包+可拆分的物品or不同面值的钱找零
解法:每次选单价最高的,最后一次塞到满为止
一元、五角、一角可以贪心求解,但若面值为1.1元、0.5元、0.1元则贪心求解可能不是最优解eg:3.7=1.1*3+0.1*4=1.1*2+0.5*3
2、活动时间安排问题
题干:给定几组活动的开始和结束时间,问某个时间段内能进行最多的活动的方式。
解法:以结束时间为贪心标准。先以结束时间排序,再逐个判断后一个活动是否与前面的集合相容,相容就要不相容就不要。
3、均分纸牌
题干:有N堆纸牌,编号分别为1,2,…,n。每堆上有若干张,各堆上取的纸牌,可以移到相邻左边或右边的堆上(最边上则只能移到一边)。现在要求找出一种移动方法,用最少的移动次数使每堆上纸牌数都一样多。
解法:先算出平均数,再从1遍历数组,不是平均数就向右边放纸牌(可以是负数张)使自己变成平均数。在从第i+1堆取出纸牌补充第i堆的过程中可能回出现第i+1堆的纸牌小于零的情况。但是无所谓,只要换顺序放(先从再右边把牌放过来),次数不变。
4、跳跃问题
题干:给定一个非负整数数组,你最初位于数组的第一个位置。数组中的每个元素代表你在该位置可以跳跃的最大长度。判断你是否能够到达最后一个位置。
解法:除非出现0,否则下一个点总是能到达的,维护一个整型farthest(初值为1),遍历这个数组,DoWhile条件为farthest≥i,farthest=max(farthest,i+a(i))。看最后的farthest大小。
(以上为高中资料文艺复兴)
循环控制行后面不能加分号,否则会直接认为没有要做的语句块。
一个不好的程序设计习惯是在循环体内修改循环变量的值。尽管这不一定会造成程序出错,但会使程序的逻辑混乱。
循环语句中的循环体要执行很多次,优化循环体对程序效率的影响非常大,特别是优化嵌套循环。
使用浮点值作为for循环变量不是一个好主意,因为在算术和比较中比较细微。由于四舍五入的错误,循环可能不会遍历您期望的值。(float和double看似比int精确,但是实际上他们经过了四舍五入而int才是真真正正的精确值)
很多例题
在数组定义中特别要注意的是,数组的元素个数必须是编译时的常量(因为编译器要知道该申请多少内存),即在程序中以常量或常量表达式的形式出现。也就是说,元素个数在写程序时已经确定。
*怎么定义不定数目的数组呢?用new int和指针。详见后面指针的部分。
1
2
int * num = new int [ values ];
delete [] num ; //用完之后要记得释放,当程序退出定义该变量的板块后,该变量仍然存在,若反复这样做,会造成“内存泄漏”。而申请的一般的数组在用完后会自动释放。
1
2
3
4
5
6
#define LEN1 10
const int LEN2 = 5 ;
constexpr int LEN3 = 666 ;
double Array1 [ LEN1 ] , Array2 [ LEN2 ] , Array3 [ LEN3 ]; // 这些都行
int LEN4 = 3 ;
double Array4 [ LEN4 ]; // 这个就不可以
1
2
3
4
5
//这种给定初值的方法称为列表初始化
int a [ 10 ] = { 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 };
int a [ 10 ] = { 0 , 1 , 2 , 3 , 4 }; //可以对数组的一部分元素赋初值,没有赋到初值的元素的初值为0
int a [ 10 ] = { 0 }; //简便地表示全是0
int a [ ] = { 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 }; //在对全部数组元素赋初值时,可以不指定数组大小,系统根据给出的初值的个数确定数组的规模。
注意,跳逗号以不赋值是不合法的 int array[10]={0,1, ,2,3}; 不行。超出规模的赋值也是不合法的。
在int main()外面定义数组会默认直接给初值0。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
#include<iostream>
using namespace std ;
int main (){
int qn [ 4 ] = { 0 }; //申请普通数组
int xn [ 5 ] = { 0 };
int * pn = new int [ 4 ]; //申请动态数组
cout <<& pn << " " <<& pn + 1 << " " <<& pn + 2 << " " <<& pn + 3 << endl ;
//上面这个输出的是指针的地址,+1表示往后一个指针的大小(8字节)
cout << pn << " " << pn + 1 << " " << pn + 2 << " " << pn + 3 << endl ;
cout <<& pn [ 0 ] << " " <<& pn [ 0 ] + 1 << " " <<& pn [ 0 ] + 2 << " " <<& pn [ 0 ] + 3 << endl ;
cout <<& pn [ 0 ] << " " <<& pn [ 1 ] << " " <<& pn [ 2 ] << " " <<& pn [ 3 ] << endl ;
//以上3种写法的输出完全一样,输出的是数组元素的地址,+1表示往后一个元素的内存(4字节)
cout << "------------" << endl ;
cout <<& qn << " " <<& qn + 1 << " " <<& qn + 2 << " " <<& qn + 3 << endl ;
//上面这个是一个没有意义的用法,+1表示往后一整个数组的长度的内存(4*4字节).
//这体现了普通数组和动态数组的区别.普通数组的&qn+2是没意义的,甚至可能会恰好报一个别人的地址.
cout << qn << " " << qn + 1 << " " << qn + 2 << " " << qn + 3 << endl ;
cout <<& qn [ 0 ] << " " <<& qn [ 0 ] + 1 << " " <<& qn [ 0 ] + 2 << " " <<& qn [ 0 ] + 3 << endl ;
cout <<& qn [ 0 ] << " " <<& qn [ 1 ] << " " <<& qn [ 2 ] << " " <<& qn [ 3 ] << endl ;
//以上3种写法的输出完全一样,输出的是数组元素的地址,+1表示往后一个元素的内存(4字节)
cout << "------------" << endl ;
cout <<& xn << " " <<& xn + 1 << " " <<& xn + 2 << " " <<& xn + 3 << endl ;
//这与前面那个没有意义的用法对照,证明了+1表示往后一整个数组的长度的内存(4*5字节)
delete [] pn ;
}
//输出
//0x7ffeea0165a0 0x7ffeea0165a8 0x7ffeea0165b0 0x7ffeea0165b8
//0x7f90d0d04080 0x7f90d0d04084 0x7f90d0d04088 0x7f90d0d0408c
//0x7f90d0d04080 0x7f90d0d04084 0x7f90d0d04088 0x7f90d0d0408c
//0x7f90d0d04080 0x7f90d0d04084 0x7f90d0d04088 0x7f90d0d0408c
//------------
//0x7ffeea0165d0 0x7ffeea0165e0 0x7ffeea0165f0 0x7ffeea016600
//0x7ffeea0165d0 0x7ffeea0165d4 0x7ffeea0165d8 0x7ffeea0165dc
//0x7ffeea0165d0 0x7ffeea0165d4 0x7ffeea0165d8 0x7ffeea0165dc
//0x7ffeea0165d0 0x7ffeea0165d4 0x7ffeea0165d8 0x7ffeea0165dc
//------------
//0x7ffeea0165b0 0x7ffeea0165c4 0x7ffeea0165d8 0x7ffeea0165ec
C++ 11标准中,为了解决 const 关键字的双重语义问题,保留了 const 表示“只读”的语义,而将“常量”的语义划分给了新添加的 constexpr 关键字。因此 C++11 标准中,建议将 const 和 constexpr 的功能区分开,即凡是表达“只读”语义的场景都使用 const,表达“常量”语义的场景都使用 constexpr。
1
2
3
4
5
6
7
8
9
10
#include <iostream>
using namespace std ;
int main ()
{
int a = 10 ;
const int & con_b = a ;
cout << con_b << endl ; //输出10
a = 20 ;
cout << con_b << endl ; //输出20
} //这个例子说明了只读不一定得到常量。程序中用 const 修饰了 con_b 变量,表示该变量“只读”,即无法通过变量自身去修改自己的值。但这并不意味着 con_b 的值不能借助其它变量间接改变,通过改变 a 的值就可以使 con_b 的值发生变化。
在目前的阶段,其实写哪个无所谓。
不要写int n=10; int array[n];这是不对的,编译器不会知道到底要多大,只会预估一下然后给一个。
在程序设计语言中,序号被称为下标。“数组名[下标]”被称为下标变量。因此定义了一个数组,相当于定义了一组变量。注意,第一个下标是0。
定义数组就是定义了一块连续的空间,空间的大小等于元素个数乘以每个元素所占的空间大小。数组元素按序存放在这块空间中。C++并不保存每个下标变量的地址,而只保存整个数组的起始地址。数组名对应着存储该数组的空间的起始地址。在引用变量时,系统要自己去计算对应的地址。
注意:C++语言不检查数组下标的合法性 。例如,定义数组int intarray [10];合法的下标范围是0~9,但如果你引用intarray[10],系统不会报错。若数组intarray的起始地址是1000,引用intarray[10]时,系统会对地址为1040的内存单元进行操作,而1040可能是另一个变量的地址,这个问题称为下标越界 。因此在操作数组时,程序员必须保证下标的合法性,否则程序的运行会出现不可预知的结果。
数组可以不完全用完所有的元素,定义的数组大小称为数组的配置长度 ,而真正使用的部分称为数组的有效长度 。
C++11中,范围for不仅可以遍历一组列出的数据,还可以遍历数组的所有元素。
1
2
3
int a [ 10 ];
for ( int x : a ) cout << x << '\t' ; //该语句表示让变量x的值从a[0]变到a[9]。
for ( auto x : a ) cout << x << '\t' ; //另,这样也可以
一维数组的一个重要操作就是在数组中检查某个特定的元素是否存在。如果找到了,则输出该元素的存储位置,即下标值。这个操作称为查找。
最差的情况要计算n次
最差的情况要计算[ln n]+1次
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#include <iostream>
using namespace std ;
int main ()
{
int low , high , mid , x ;
int array [ ] = { 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 };
cout << "请输入要查找的数据:" ; cin >> x ;
low = 0 ; high = 9 ;
while ( low <= high ) { // 查找区间存在
mid = ( low + high ) / 2 ; // 计算中间位置
if ( x == array [ mid ] ) break ; // 找到
if ( x < array [ mid ]) high = mid - 1 ; else low = mid + 1 ; // 修改查找区间
}
if ( low > high ) cout << "没有找到" << endl ;
else cout << x << "的位置是:" << mid << endl ;
return 0 ;
}
二分的思想可以用于多种情景,不一定是一个有序数组,只需找到一个分隔点,把序列分成两个类别
一个例题:N个同学,能力值为Ai,分成M组(不能换顺序),要求各组能力值的和的最大值最小,给出这个能力值的和
1
2
3
4
5 3
4 2 4 5 1 //输入样例
6 //输出样例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
#include<iostream>
using namespace std ;
int main (){
int a [ 10005 ] = { 0 };
int n , m ;
cin >> n >> m ;
int sum = 0 , max = 0 ;
for ( int i = 1 ; i <= n ; i ++ ){
cin >> a [ i ];
sum += a [ i ];
if ( a [ i ] > max ){
max = a [ i ];
}
} //输入部分
//下面用能力值和的最大值作为指标来对分
int ll = max , rr = sum ; //可能的最小值和最大值
int mid = ( ll + rr ) / 2 ;
int ans ;
int tmpsum = 0 , tmpgroup = 0 ; //组的能力值,组数
while ( ll <= rr ){ //这个等号也是必要的?
mid = ( ll + rr ) / 2 ;
tmpsum = 0 ;
tmpgroup = 1 ;
for ( int i = 1 ; i <= n ; i ++ ){
if ( tmpsum + a [ i ] <= mid ){
tmpsum += a [ i ]; //没到目标最大能力值就继续要人
} else {
tmpgroup ++ ;
tmpsum = a [ i ]; //超了就换组,确保每组的能力值小于等于mid
}
}
if ( tmpgroup <= m ){ //如果组数比给定值小,说明分得太宽,说明mid猜大了
ans = mid ;
rr = mid - 1 ; //这个减1是必要的,以确保能弹出循环
}
else if ( tmpgroup > m ){ //如果组数比给定值大,说明分得太密,说明mid猜小了
ll = mid + 1 ; //这个加1是必要的,以确保能弹出循环
}
}
cout << ans ;
} //注意这个代码的低鲁棒性
应用选择排序 时,每次选择一个元素放在它最终要放的位置。如果要将数据按非递减次序排列,一般的过程是先找到整个数组中的最小的元素,并把它放到数组的起始位置,然后在剩下的元素中找最小的元素并把它放在第二个位置上,对整个数组继续这个过程,最终将得到按从小到大顺序排列的数组。不同的最小元素选择方法得到不同的选择排序算法 。直接选择排序是选择排序算法中最简单的一种,就是在找最小元素时采用最原始的方法——顺序查找。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
#include <iostream>
using namespace std ;
int main ( )
{
int lh , rh , k , tmp ;
int array [ ] = { 2 , 5 , 1 , 9 , 10 , 0 , 4 , 8 , 7 , 6 };
for ( lh = 0 ; lh < 10 ; ++ lh ) { // 依次将正确的元素放入array[lh]
rh = lh ;
for ( k = lh ; k < 10 ; ++ k ) // 找出从lh到最后一个元素中的最小元素的下标rh
if ( array [ k ] < array [ rh ] ) rh = k ;
tmp = array [ lh ]; array [ lh ] = array [ rh ]; array [ rh ] = tmp ; //交换lh和rh的值
}
for ( lh = 0 ; lh < 10 ; ++ lh ) cout << array [ lh ] << ' ' ;
return 0 ;
}
要$n^2$次运算
从头到尾比较相邻的两个元素,将小的换到前面,大的换到后面。经过了从头到尾的一趟比较,就把最大的元素交换到了最后一个位置。这个过程称为一趟起泡。再从头开始到倒数第二个元素进行第二趟起泡。比较相邻元素,如违反排好序后的次序,则交换相邻两个元素。经过了第二趟起泡,又将第二大的元素放到了倒数第二个位置,……,依次类推,经过第n-1趟起泡,将倒数第n-1个大的元素放入位置1。此时,最小的元素就放在了位置0,完成排序。
怎么判断提前结束 ?如果在一趟起泡过程中没有发生任何数据交换,则说明这批数据中相邻元素都满足前面小后面大的次序,也就是这批数据已经是排好序了,无需再进行后续的起泡过程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
#include <iostream>
using namespace std ;
int main ()
{
int a [ ] = { 0 , 3 , 5 , 1 , 8 , 7 , 9 , 4 , 2 , 10 , 6 };
int i , j , tmp ;
bool flag ; //记录一趟起泡中有没有发生过交换
for ( i = 1 ; i < 11 ; ++ i ) { // 控制10次起泡
flag = false ;
for ( j = 0 ; j < 11 - i ; ++ j ) // 一次起泡过程
if ( a [ j + 1 ] < a [ j ]){
tmp = a [ j ]; a [ j ] = a [ j + 1 ]; a [ j + 1 ] = tmp ;
flag = true ;
}
if ( ! flag ) break ; //一趟起泡中没有发生交换,排序提前结束
}
for ( i = 0 ; i < n ; ++ i ) cout << a [ i ] << ' ' ;
return 0 ;
}
数组的元素可以是任何类型。如果数组的每一个元素又是一个数组,则被称为多维数组。最常用的多维数组是二维数组,即每一个元素是一个一维数组的一维数组。
1
2
3
4
5
类型名 数组名 [ 行数 ][ 列数 ]; //定义二维数组的格式
int a [ 3 ][ 4 ] = { 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 , 11 , 12 }; //先是第1行的所有元素值,接着是第2行的所有元素值,以此类推。
int a [ 3 ][ 4 ] = { { 1 , 2 , 3 , 4 }, { 5 , 6 , 7 , 8 }, { 9 , 10 , 11 , 12 }}; //可以通过花括号把每一行括起来,使这种初始化方法表示得更加清晰。
int a [ 3 ][ 4 ] = { 1 , 2 , 3 , 4 , 5 }; //初始化列表中的数值按行序依次赋给每个元素,没有赋到初值的元素初值为0。
int a [ 3 ][ 4 ] = { { 1 , 2 },{ 3 , 4 },{ 5 }}; //对每一行的部分元素赋初值,没赋的就是0。
同一维数组一样,0是第一行(列)。
同一维数组一样,在引用二维数组的元素时,计算机也不检查下标的合法性。下标的合法性必须由程序员自己保证。
也是申请了一块连续的空间。在这块空间中,先放第0行,再放第1行……每一行又是一个一维数组,先放第0列,再放第1列……
比如用于矩阵。这比浙江高考不允许用二维数组,而用一维数组去存矩阵要高明多了。
C++中的字符串常量是用一对双引号括起来、由'\0'作为结束符的一组字符。
1
char ch [ ] = { 'H' , 'e' , 'l' , 'l' , 'o' , ',' , 'w' , 'o' , 'r' , 'l' , 'd' , '\0' };
可以这么存“Hello,World”。记住数组的长度是字符个数加1,因为最后有一个'\0'。
但是这个太麻烦了,下面这样写即可,系统都会自动分配一个12个字符的数组,把这些字符依次放进去,最后插入'\0'。
1
2
char ch [ ] = { "Hello,world" };
char ch [ ] = "Hello,world" ;
不包含任何字符的字符串称为空字符串。空字符串用一对双引号表示,即"''。空字符串并不是不占空间,而是占用了1字节的空间,这个字节中存储了一个'\0'。
注意,在C++中,'a'和"a"是不一样的。事实上,这两者有着本质的区别。前者是一个字符常量,在内存占1字节,里面存放着字符a的内码值,而后者是一个字符串,用一个字符数组存储,它占2字节的空间;第一个字节存放了字母a的内码值,而第二个字节存放了'\0'。
1
2
3
4
5
6
7
8
9
char ch [ 10 ];
cin >> ch ; //键盘输入的字符依次存放在ch数组中,直到读入一个空白字符为止,会自动补\0,如果字符串数组规模不够大,就会直接写到外面去。
//问题在于不能输入空白字符(空格回车Tab),且无法控制输入串的长度。
cout << ch ; //实际是传入ch的地址,ch数组中的字符依次被显示在显示器上,直到遇到'\0'。如果ch数组范围内没有\0,可能会abort(MacVscode爆,WinVscode不爆)。
cin . getline ( ch , 10 , '.' ) //三个参数依次为字符数组、数组长度、结束标记。可以读空白字符
//直到遇到了指定的结束标记或到达了数组长度减1(因为字符串的最后一个字符必须是'\0',必须为'\0'预留空间)则停止输入,这样可以输入空白字符。 另,若不定义,默认的结束标记是回车。
//注意这么写时,如果没有EOF或者'.'或者读到9个字符是不会结束的,如果回车则会把回车当作字符读进去。
//cin.getline会提走结束符并丢弃。
cin . get ( ch , 10 , '.' ) //效果几乎相同,但不会把结束符提出来
cin无法控制输入串的长度导致的问题:>>操作将一个个输入的字符依次放入字符数组,直到遇到空白字符,在此过程中不检查输入的字符个数是否超过数组长度。输入的字符个数超过数组长度,就会占用不属于该数组的空间,这种现象称为内存溢出 。内存溢出会导致一些无法预知的错误。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
char ch ;
cin . get ( ch ) //ch是istream对象,只接收字符,在到达EOF时不会把EOF交给ch。到达EOF时函数返回值为false,正常读入时函数返回值为true
ch = cin . get () //ch会接收任何,在到达EOF时把EOF交给ch
// cin.get是重载函数
// 在使用cin.get时,不论有没有把值拿走,都读取了一下,下一次读就是下一个字符了
// 注意用cin>>读取的时候,分隔符不会被读,比如回车不会被读,如果cin>>和cin.get混用,记得空放一个cin.get把那个回车耗费掉
while ( cin . get ( ch )){
... 对 ch操作 ...
} //一种读取一串字符的方法
while (( ch = cin . get ()) != EOF ){
... 对 ch操作 ...
} //另一种读取一串字符的方法
//注意上面两种方法需要在字符串的末位自己填'\0',cin>>和getline会自动创建'\0'
//在IDE中输入时,可以用ctrl+Z或者ctrl+C或者ctrl+D模拟EOF
让我们引入#include(C语言处理字符串的函数库)。
函数
作用
strcpy(dst, src)
将字符串从 src 复制到 dst 。函数的返回值是 dst 的地址
strncpy(dst, src, n)
至多从 src 复制 n 个字符到 dst。函数的返回值是 dst 的地址
strcat(dst, src)
将 src 拼接到 dst 后。函数的返回值是 dst 的地址
strncat(dst, src, n)
从 src 至多取 n 个字符拼接到 dst 后。函数的返回值是 dst 的地址
strlen(s)
返回字符串 s 的长度, 即字符串中的字符个数,不计\0,也不从0开始数
strcmp(s1, s2)
比较 s1 和 s2。如果 s1>s2 返回值为正数, sl=s1 返回值为 0," "s1 < s2 返回值为负数
strncmp(s1, s2, n)
与strcmp 类似, 但至多比较 n 个字符
与trchr(s, ch)
返回一个指向 s 中第一次出现 ch 的地址
strrchr(s, ch)
返回一个指向 s 中最后一次出现 ch 的地址
strstr(s1, s2)
返回一个指向 s1 中第一次出现 s2 的地址
使用strcpy和strcat函数时,必须注意dst必须是一个字符数组,不可以是字符串常量,而且该字符数组必须足够大,能容纳被复制或被拼接后的字符串,否则将出现内存溢出,程序会出现不可预知的错误。
太LOW了,让我们祭出C++的类string!终于能不用那么愚蠢的char数组了,#include,然后用string就好了。
略
注意,数组名是指针常量,不能直接把另一个数组名赋值给它。
C++数组的下标是从0开始,n个元素的数组的合法下标范围是0到n-1。
字符串是用数组存储。注意数组的长度必须比字符串中的字符个数多1。
字符串不能用内置运算符操作,必须使用cstring库中提供的函数或自己编程解决。
VSstudio在debug模式下会给未初始化的栈内存写入0xcc,给未初始化的堆内存写入0xcd,堆内存的周围(前后各 4 个 Byte)会被写入 0xfd,被销毁的堆内存写入0xdd。0xcccc是GBK的“烫”,0xcdcd是GBK的“屯”。
图形渲染时,为了计算向量的模,常用到“平方根的倒数”运算,下面是一个古早的优化(如今已经有CPU层面的优化,不必用此)
1
2
3
4
5
6
7
8
9
10
11
12
float Q_rsqrt ( float number ) //针对IEEE 754标准格式的32位浮点数设计
{
long i ;
float x2 , y ;
const float threehalfs = 1.5F ; //F表示告诉编译器将这个数按float处理,因为默认的小数是double
x2 = number * 0.5F ;
y = number ;
i = * ( long * ) & y ; // evil floating point bit level hacking //将浮点数取别名存储为整数
i = 0x5f3759df - ( i >> 1 ); // what the fuck? //>>逻辑右移,高位补0,即转换为整数的数除以2
y = * ( float * ) & i ;
y = y * ( threehalfs - ( x2 * y * y ) ); // 1st iteration
// y = y * ( threehalfs - ( x2 * y * y ) ); // 2nd iteration, this can be removed
要开方的数都是正数,故符号位都是0,则转换成整数来看也是正数。
0x5f3759df这一行用极优化的做法实现了对值的第一次预估,后面转换回浮点型做一次牛顿迭代。
为什么这个预估相当好呢?符号位为0,E是指数部分,M是尾数部分。$I=2^{23}E+M,F=(1+0.M_{[2]})2^{E-127}=(1+M/2^{23})\times 2^{E-127}$,给F取对数得$log_2F=(E-127)+log_2(1+M/2^{23})=(E-127)+M/2^{23}+\delta=(M+2^{23}E)/2^{23}-127+\delta=I/2^{23}-127+\delta$。欲求$F'=1/\sqrt{F}$,有$log_2F'=-1/2 log_2F=-1/2*(I/2^{23}-127+\delta)$,与此同时$log_2F'=I'/2^{23}-127+\delta'$,故得$I'=-I/2+R,R=2^{23}(127*3/2-\delta'-\delta/2)$,$\delta=ln(1+x)-x,x\in[0,1)$,取$\delta=\delta'=0.0450465$,算得$R=1,597,463,007=$0x5f3759df。
牛顿迭代:设 $r$ 是 $f(x)=0$ 的根, 选取 $x_0$ 作为 $r$ 的初始近似值, 过点 $\left(x_0, f\left(x_0\right)\right)$ 做曲线 $y=f(x)$ 的切线 $L$, $L: y=f\left(x_0\right)+f^{\prime}\left(x_0\right)\left(x-x_0\right)$, 则 $L$ 与 $x$ 轴交点的横坐标 $x_1=x_0-\frac{f\left(x_0\right)}{f^{\prime}\left(x_0\right)}$, 称 $x_1$ 为 $r$ 的一次近似值。过点 $\left(x_1, f\left(x_1\right)\right)$ 做曲线 $y=f(x)$ 的切线, 并求该切线与 轴交点的横坐标 $x_2=x_1-\frac{f\left(x_1\right)}{f^{\prime}\left(x_1\right)}$, 称 $x_2$ 为 $\mathrm{r}$ 的二次近似值。重复 以上过程, 得 $r$ 的近似值序列, 其中, $x_{n+1}=x_n-\frac{f\left(x_n\right)}{f^{\prime}\left(x_n\right)}$ 称为 $r$ 的 $n+1$ 次近似值, 上式称为牛顿迭代公式。用牛顿迭代法解非线性方程, 是把非线性方程 $f(x)=0$ 线性化的一种近似方法。把 $f(x)$ 在点 $x_0$ 的某邻域内展开成泰勒级数 $f(x)=f\left(x_0\right)+f^{\prime}\left(x_0\right)\left(x-x_0\right)+\frac{f^{\prime \prime}\left(x_0\right)\left(x-x_0\right)^2}{2 !}+\cdots+\frac{f^{(n)}\left(x_0\right)\left(x-x_0\right)^n}{n !}+R_n(x)$, 取其线性部分 (即泰勒展开的前两项), 并令其等于 0 , 即 $f\left(x_0\right)+f^{\prime}\left(x_0\right)\left(x-x_0\right)=0$, 以此作为非线性方程 $f(x)=0$ 的近似方程, 若 $f^{\prime}\left(x_0\right) \neq 0$, 则其解为 $x_1=x_0-\frac{f\left(x_0\right)}{f^{\prime}\left(x_0\right)}$, 这样, 得到牛顿迭代法的一个迭代关系式: $x_{n+1}=x_n-\frac{f\left(x_n\right)}{f^{\prime}\left(x_n\right)}$ 。已经证明, 如果是连续的, 并且待求的零点是孤立的, 那么在零点周围存在一个区域, 只要初始值位于这个邻近区域内, 那 么牛顿法必定收敛。并且, 如果不为 0 , 那么牛顿法将具有平方收敛的性能. 粗略的说, 这意味着每迭代一次, 牛顿法结果的有效数字将增加一倍。
在程序设计中,通常采用一种称为自顶向下分解的方法,将一个大问题分解成若干个小问题,把解决小问题的程序先写好,每个解决小问题的程序就是一个函数。在解决大问题时,不用再考虑每个小问题如何解决,直接调用解决小问题的函数就可以了。这样可以使解决整个问题的程序的主流程变得更短、更简单,逻辑更清晰。
又及,函数可以多次调用,以实现便利。
调用库:标准库函数用方括号,自定义函数库用双引号。
1
2
3
4
5
类型名 函数名 ( 形式参数表 )
{
变量定义部分
语句部分
}
形式参数表若有多个要定义的参数,用逗号隔开,引用函数的时候输入的参数也是逗号隔开。
参数可以是非引用形参 (int p。只是用输入的实参的值来初始化形参,不会修改实参的值)、指针形参 (int *p。指针指向的地址不变,但指向地址的值可变)、引用形参 (Int &a。直接和实参绑定,而非输入实参的副本,对形参的操作直接对实参造成改变)。
实际参数和形式参数的对应过程称为参数的传递。C++中参数的传递方式有两种:值传递和引用传递。
函数也可以没有返回值,这种函数通常被称为过程,此时,返回类型用void表示。
函数名是一个标识符,命名规则与变量名相同。
当函数的返回类型不是void时,函数必须返回一个值。函数值的返回可以用return语句实现。
1
2
return 表达式 ;
return ( 表达式 ); //两种都行
遇到return语句表示函数执行结束,将表达式的值作为返回值。如果函数没有返回值,则return语句可以省略表达式,仅表示函数执行结束。
返回布尔值的函数也称为谓词函数 。谓词函数的命名一般以is开头,表示判断。例如,判断是否为大写字母的函数可命名为isUpper,判断是否是数字的函数可命名为isDigit。
函数的执行称为函数调用。但在函数调用前,必须先声明函数原型。
被调用的函数定义在调用该函数的函数的前面。当程序有很多函数组成时,这个次序安排是很困难的,甚至是不可能的。C++用函数原型声明来解决函数调用的正确性检查问题。
1
2
3
4
返回类型 函数名 ( 形式参数说明 );
char func ( int , float , double ); //这是一个例子
double sin ( double angleInRadians ); //这是另一个例子
//在函数原型声明中,每个形式参数类型后面还可以跟一个参数名,该名字可标识特定的形式参数的作用,这可以为程序员提供一些额外的信息。虽然形式参数的名字为使用该函数的程序员提供了重要的信息,但对程序无任何实质性的影响。
系统标准库中的函数原型的声明包含在相关的头文件中,这就是为什么在用到系统函数时,要在源文件头上包含此函数所属的库的头文件。用户自己定义的函数一般在源文件头上声明,或放在用户自己定义的头文件中。
这是函数调用的形式。
在C++的函数调用中,如果有多个实际参数要传给函数,而每个实际参数都是表达式。那么,在参数传递前首先要计算出这些表达式的值,再进行参数传递。但是,C++并没有规定这些实际参数表达式的计算次序。故f(++x,x)这样的写法是危险的,可能从左往右算也可能从右往左算,导致++x何时对x作出修改不确定。
无返回值的函数,即过程,通常作为语句出现,即直接在函数调用后加一个分号,形成一个表达式语句;有返回值的函数通常作为表达式的一部分。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
//多函数程序的组成及函数的使用
#include <iostream>
using namespace std ;
void PrintStar ( int ); //函数原型声明
//主程序
int main ()
{
int n ;
cout << "请输入要打印的行数:" ;
cin >> n ;
printstar ( n ); //函数调用,n为实际参数
return 0 ;
}
//函数:PrintStar
//用法:PrintStar(numOfLine)
//作用:在屏幕上显示一个由numOfLine行组成的三角形
void PrintStar ( int numOfLine )
{
int i , j ;
for ( i = 1 ; i <= numOfLine ; ++ i ){
cout << endl ;
for ( j = 1 ; j <= numOfLine - i ; ++ j ) cout << ' ' ;
for ( j = 1 ; j <= 2 * i - 1 ; ++ j ) cout << "*" ;
}
cout << endl ;
}
书上样例,照办就行。
当在main函数或其他函数中发生函数调用时,系统依次执行如下过程。
• 在main函数或调用函数中计算每个实际参数值。
• 用实际参数初始化对应的形式参数。在初始化的过程中,如果形式参数和实际参数类型不一致,则完成自动类型转换,将实际参数转换成形式参数的类型。
• 依次执行被调函数的函数体的每条语句,直到遇见return语句或函数体结束。
• 计算return后面表达式的值,如果表达式的值与函数的返回类型不一致,则完成类型的转换。
• 回到调用函数。在函数调用的地方用return后面的表达式的值替代,继续调用函数的执行。
当发生函数调用时,系统会为该函数分配一块内存空间,称为一个帧 (main函数也一样)。当函数执行结束时,系统回收分配给该函数的帧,因此所有存储在这块空间中的变量也就都消失了。另外,程序在同一时间只能访问一个帧,举个例子,main()里面调用了max(),而在计算max()的过程中,程序能够访问的变量就是max函数中的那些变量,而main函数的那些变量暂时不能访问(所以要用形参把要访问的东西传到max的帧中)。
退出帧时,会把这帧中申请的自动变量释放掉。
调用可以嵌套,甚至可以调用main。
无论何时一个函数被调用,它定义的变量都创建在一个称为栈 的独立内存区域。调用一个函数相当于从栈中分配一个新的帧,并且放在代表其他活动函数的帧上面。从函数返回相当于拿掉它的帧,并继续在调用者中执行。
变量可以被使用的程序部分称为它的作用域 。
一个花括号就是一个块(比如for,或者硬写一个花括号套),块内的申请的变量只在块内使用。
在函数内部定义的变量,包括形式参数,仅仅存活于一帧中,只能在函数内部引用,因此被称为局部变量 。C++程序的主函数main中定义的变量也是局部的,只有在主函数中才能使用。在一个程序块(花括号为界)中也可以定义变量,这些变量值在本程序块中有效。
在C++中,变量定义也可以出现在所有函数定义之外,以这种方式定义的变量称为全局变量 。定义本身看起来跟局部变量一样,只是它们是出现在所有函数的外面,通常是在文件开始处。全局变量不受函数调用的影响,存储在一个始终有效的独立的内存区域,不会被包含局部变量的帧覆盖,程序中每个函数都能看到并操作。
全局变量和局部变量可以有相同的名字。当全局变量和局部变量同名时,在局部变量的作用域中全局变量被屏蔽。如果就是想用全局的变量,在变量名前加::(作用域运算符)。上一级定义的变量可以被下一级访问。同一级不能有同名变量,函数内定义的变量也不能与形参同名。
变量有两个属性,数据类型和存储类别。
按变量在计算机内的存储位置来分,变量又可以分为自动变量(auto)、静态变量(static)、寄存器变量(register)和外部变量(extern)。变量的存储位置称为变量的存储类别 。
这是C++中完整的变量定义格式。
栈优先分配高地址,栈的空间可以被函数反复使用。
内存:高地址->argc,argv|栈...... 都是动态变量 ......堆|静态变量|常量|程序代码<-低地址
如果不声明,那么都是自动变量。存储在栈的帧中,自动分配和回收空间。
局部变量和全局变量都可以被定义为静态的。
如果在一个源文件的头上定义了一个全局变量,则该源文件中的所有函数都能使用该全局变量。不仅如此,事实上该程序中的其他源文件中的函数也能使用该全局变量。但在一个结构良好的程序中,一般不希望多个源文件共享某一个全局变量。要做到这一点,可以使用静态的全局变量。
1
static int x ; // 这样定义的全局x是这个文件私有的。其他源文件中的函数不能引用
如果把一个局部变量定义为static,该变量就不再存放在函数对应的帧中,而是存放在全局变量区。当函数执行结束时,该变量不会消亡。在下一次函数调用时,也不再创建该变量以及重新初始化,而是继续使用原空间中的值。这样就能把上一次函数调用中的某些信息带到下一次函数调用中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
#include<iostream>
using namespace std ;
int f ( int a );
int main ()
{
int a = 2 ;
for ( int i = 0 ; i < 3 ; ++ i ) cout << f ( a ) << endl ;
return 0 ;
}
int f ( int a )
{
int b = 0 ;
static int c = 3 ; //再次定义的时候没有刷新c的值回到3
b = b + 1 ; c = c + 1 ;
cout << b << c ;
return ( a + b + c );
} //输出147\n258\n169
• 未被程序员初始化的静态变量都由系统初始化为0。
• 局部静态变量的初值是编译时赋的。当运行时重复调用函数时,由于没有重新分配空间,因此也不做初始化。!!!
• 虽然局部静态变量在函数调用结束后仍然存在,但其他函数不能引用它。
• 局部的静态变量在程序执行结束时消亡。如果程序中既有静态的局部变量又有全局变量,系统先消亡静态的局部变量,再消亡全局变量。
全局变量可以通过static声明为某一源文件私有的,函数也可以。如果在函数定义时,在原型前面加上static,那么这个函数只有被本源文件中的函数调用,而不能被其他源文件中的函数调用。
一般情况下,变量的值都存储在内存中。当程序用到某一变量时,由控制器发出指令将该变量的值从内存读入CPU的寄存器进行处理,处理结束后再存入内存。为了节省这段时间,可以直接把变量存到寄存器中去。
1
register int x ; //定义寄存器变量的例子
在使用寄存器变量时,必须注意只有局部自动变量才能定义为寄存器变量,全局变量和静态的局部变量是不能存储在寄存器中的。
由于各个计算机系统的寄存器个数都不相同,程序员并不知道可以定义多少个寄存器类型的变量,因此寄存器类型的声明只是表达了程序员的一种意向,如果系统中无合适的寄存器可用,编译器就把它设为自动变量。现在的编译器通常都能识别频繁使用的变量。作为优化的一个部分,编译器并不需要程序员进行register的声明,就会自行决定是否将变量存放在寄存器中。
外部变量一定是全局变量。全局变量的作用域是从变量定义处到文件结束。如果在定义点以前的函数或另一源文件中的函数也要使用该全局变量,则在引用之前,应该对此全局变量用关键字extern进行外部变量声明,否则编译器会认为使用了一个没有定义过的变量。就是声明一个不在本模块定义的变量,定义不需要写extern,只有在另一个文件声明的时候需要写extern。如果想把全局变量声明为文件私有的,加static。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#include <iostream>
using namespace std ;
void f ();
int main ()
{
extern int x ; //如果没有这行,则会报错。另外,类型名可以忽略不写,直接extern x即可。
// 把外部变量声明和函数的声明写在一起也是一个不错的选择
f ();
cout << "in main(): x= " << x << endl ;
return 0 ;
}
int x ; //全局变量定义在后面或者定义在别的源文件中
//如果定义在别的源文件中,而那个地方误写了static int x;则会报“找不到外部符号int x”
void f (){ cout << "in f(): x= " << x << endl ;}
在使用外部变量时,用术语外部变量声明 而不是外部变量定义。变量的定义和变量的声明是不一样的。变量的定义是根据说明的数据类型为变量准备相应的空间,而变量的声明只是说明该变量应如何使用,并不为它分配空间,就如函数原型声明一样。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <iostream>
using namespace std ;
int average ( int array [ 10 ]); //函数原型声明,10可略写
int main (){
int i , score [ 10 ];
cout << "请输入10个成绩:" << endl ;
for ( i = 0 ; i < 10 ; i ++ ) cin >> score [ i ];
cout << "平均成绩是:" << average ( score ) << endl ; //函数调用
return 0 ;
}
int average ( int array [ 10 ]){ //函数定义,10可略写
int i , sum = 0 ;
for ( i = 0 ; i < 10 ; ++ i ) sum += array [ i ]; //使用形参
return sum / 10 ;
}
//总而言之,数组作为参数和数值作为参数没啥大区别
数组名代表的是数组在内存中的起始地址。按照值传递的机制,在参数传递时用实际参数的值初始化形式参数,即将作为实际参数的数组的起始地址赋给形式参数的数组名,这样形式参数和实际参数的数组具有同样的起始地址,也就是说形式参数和实际参数的数组事实上是同一个数组 。在函数中对形式参数数组的任何修改实际上是对实际参数的修改。所以数组传递的本质是仅传递了数组的起始地址 ,并不是将作为实际参数的数组中的每个元素对应传送给形式参数的数组的元素。
传递一个数组需要两个参数:数组名和数组大小。数组名给出数组的起始地址,数组大小给出该数组的元素个数。由于数组传递本质上是首地址的传递,真正的元素个数是作为另一个参数传递的(比如程序员要再写一个int size传过去,或者在编写函数是注意不要下标越界,否则函数自己是不会管数组的规模的),因此形式参数中数组的大小是无意义的,通常可省略(比如上面代码可略去10不写)。
二维数组可以看成是由一维数组组成的数组。当二维数组作为参数传递时,第一维的个数可以省略,第二维的个数必须指定。
数组参数实际上传递的是地址这一特性非常有用,它可以在函数内部修改作为实际参数的数组元素值。
由于字符数组中保存的是一个字符串,字符串有结束符'\0',故字符数组不用传规模。
在C++中,允许在定义或声明函数时,为函数的某个参数指定默认值。当调用函数时,没有为它指定实际参数时,系统自动将默认值赋给形式参数。
1
void print ( int value , int base = 10 ); //这是一个函数声明,这还规定了base的默认值是10
注意:在设计函数原型时,应把有默认值的参数放在参数表的右边;一旦某个参数指定了默认值,它后面的所有参数都必须有默认值 。(因为调用的时候只是用逗号隔开,如果默认值间隔着赋,编译器不知道到底实参要给哪个形参。)
注意:参数的默认值是提供给函数的调用者使用的,而编译器是根据函数原型声明确定函数调用是否合法的,所以在函数定义 时指定默认值是没有意义的 ,除非该函数定义还充当了函数声明的作用。若两处都定义了,以声明处的为准 。
注意:在不同的源文件中,可以对函数的参数指定不同的默认值;但在同一源文件中对每个函数的每一个参数只能指定一个默认值。
由于函数调用需要系统做一些额外的工作(创建函数的帧,记录指令的跳转,分配内存和回收内存)会影响执行时的性能。如果函数比较大,运行时间比较长,相比之下,调用时的额外开销可以忽略。但如果函数本身比较小,运行时间也很短,则调用时的额外开销就显得很可观,使用函数似乎得不偿失。为此,C++提供了内联函数功能。
内联函数有函数的外表,但没有调用的开销。编译时,编译器将内联函数的代码复制到调用处来避免函数调用。内联的坏处是最后生成的代码变长。
要把一个函数定义为内联函数,只要在函数头部的返回类型前加一个关键字inline。但在使用内联函数时,必须注意内联函数必须定义在被调用之前,否则编译器无法知道应该插入什么代码。内联函数不能递归。
内联函数对编译器而言只是一个建议。编译器可以根据实际情况决定处理的方式。
C++提供了一个称为重载函数的功能。允许参数个数不同、参数类型不同或两者兼而有之的两个以上的函数取相同的函数名。两个或两个以上的函数共用一个函数名称为函数重载,这一组函数称为重载函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#include <iostream>
using namespace std ;
int max ( int a1 , int a2 );
int max ( int a1 , int a2 , int a3 );
int max ( int a1 , int a2 , int a3 , int a4 );
int main (){
cout << "max(3,5) is " << max ( 3 , 5 ) << endl ;
cout << "max(3,5,4) is " << max ( 3 , 5 , 4 ) << endl ;
cout << "max(3,5,7,9) is " << max ( 3 , 5 , 7 , 9 ) << endl ;
return 0 ;
}
int max ( int a1 , int a2 ) { return a1 > a2 ? a1 : a2 ;}
int max ( int a1 , int a2 , int a3 ){
int tmp ;
if ( a1 > a2 ) tmp = a1 ; else tmp = a2 ;
if ( a3 > tmp ) tmp = a3 ;
return tmp ;
}
int max ( int a1 , int a2 , int a3 , int a4 ){
int tmp ;
if ( a1 > a2 ) tmp = a1 ; else tmp = a2 ;
if ( a3 > tmp ) tmp = a3 ;
if ( a4 > tmp ) tmp = a4 ;
return tmp ;
}
以上是一个例子,用户不用关心数据是2个3个还是4个,只要把数据放进max就可。
重载函数为函数的用户提供了方便,但给编译器带来了更多的麻烦。编译器必须确定某一次函数调用到底是调用了哪一个具体的函数。这个过程称为绑定 (又称为联编或捆绑)。编译器首先会为这一组重载函数中的每个函数取一个不同的内部名字。当发生函数调用时,编译器根据实际参数和形式参数的匹配情况确定具体调用的是哪个函数,用这个函数的内部函数名取代重载的函数名。
要没有歧义,比如下面这个例子就会报错:
1
2
int sth ( int a , int b = 1 );
int sth ( int a );
在只有一个实参进来时,编译器还是不知道要运行什么。
如果一组重载函数仅仅是参数的类型不一样,程序的逻辑完全一样,如果用一个符号代替类型,这组函数的代码完全相同。这一组重载函数可以写成一个函数,称为函数模板。从而将写一组函数的工作减少到了写一个函数模板。
函数模板的使用和普通函数完全一样。当发生函数调用时,编译器根据实际参数的类型确定模板参数的值,将实际参数的类型取代函数模板中的模板的形式参数,形成一个真正可执行的函数。该过程称为模板的实例化。实例化形成的函数称为模板函数。
函数模板的定义都以关键字template开头,之后是用尖括号括起来的模板的形式参数声明。每个形式参数之前都有关键字class或typename(这两个在目前可互换)。
1
2
3
4
5
6
7
8
9
10
11
12
#include <iostream>
using namespace std ;
template < class T >
T max ( T a , T b ){ //生成的模板函数会用——比如int来取代这里的T
return a > b ? a : b ;
}
int main (){
cout << "max(3,5) = " << max ( 3 , 5 ) << endl ;
cout << "max(3.3, 2.5) = " << max ( 3.3 , 2.5 ) << endl ;
cout << "max('d', 'r') = " << max ( 'd' , 'r' ) << endl ;
return 0 ;
}
如果某些模板参数在函数的形式参数表中没有出现,编译器就无法推断模板实际参数的类型。这个问题可以用显式指定模板实参来解决。
1
2
3
4
5
6
7
template < class T1 , class T2 , class T3 >
T3 calc ( T1 x , T2 y ){
return x + y ;
}
calc ( 5 , 'a' ) //上面这个函数模板将会不知道该输出什么型
calc < int , char , char > ( 5 , 'a' ); //输出'f'
calc < int , char , int > ( 5 , 'a' ); //输出102
一个练习,尝试根据类型来决定函数输出的类型
1
2
3
4
5
6
7
8
9
10
11
12
13
template < typename T , typename U >
decltype ( T () + U ()) add ( T t , U u ){
return t + u ;
}
template < typename T , typename U >
auto add2 ( T t , U u ) -> decltype ( t + u ){
return t + u ;
}
int main (){
int a = 1 ; float b = 2.0 ;
auto c = add ( a , b );
}
// decltype是C++11引入的,返回变量类型
调用自身的函数称为递归函数,这种解决问题的方法称为递归程序设计。
1
2
3
if ( 递归终止的条件测试 ) return ( 不需要递归计算的简单解决方案 );
else return ( 包括调用同一函数的递归解决方案 );
//一个递归的典型范例
注意:写递归必须要有递归终止条件;必须有一个与递归终止条件相关的形参且在递归调用中越来越接近递归终止条件。
要使递归得到正确的结果,需要递归信任,信任递归函数的(上一次)调用能得到正确的结果,那么这一次也一定是正确的。
一个递归函数的执行由两个阶段组成:递归调用(拿到f(n-1)的值)和回溯(计算f(n))。
递归和for循环比,其效率是低的,因为调用开销大,而且可能重复计算一些值(用一个数组记录过程来解决)。
1
2
3
4
5
6
7
8
9
10
// 汉诺塔问题:将n个盘子从start借助于temp移动到finish
// 用法:Hanoi(64, 'A', 'B', 'C');
void Hanoi ( int n , char start , char finish , char temp ){
if ( n == 1 ) cout << start << "->" << finish << '\t' ;
else {
Hanoi ( n - 1 , start , temp , finish );
cout << start << "->" << finish << '\t' ;
Hanoi ( n - 1 , temp , finish , start );
}
}
当用递归方案解决问题时,往往需要定义一个原型与原问题稍有不同的递归函数。新的函数需要带有一些额外的、用于递归控制的参数,但这些参数对于整个问题来说并不是必需的。用户所用的函数调用了这个递归函数,并传递了这些额外参数的初值。这样的函数叫作包装函数。
如八皇后问题、分书问题。
理念就是先办着(走一步看一步并记录历史),直到办不下去了就往回走一格(写几行代码抹除走的那一步的影响,但是不再重新尝试走过的那一步)。
当遇到 main 函数中的 return 语句时,C++程序将停止执行。但其他函数结束时,程序并不会停止。程序的控制将返回到函数调用之后的位置。然而,有时候会出现一些非常少见的情况,使得程序有必要在 main 以外的函数中终止。要实现这一点,可以使用 exit 函数。
写exit(0);即可退出整个程序,并返回一个退出代码0。可以返回别的数字以表示不同的情况。
如快速排序:取基准数,然后把比它大的往一边,小的往另一边,两边再分别重复这个操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
'快速排序
Function Swap ( a as integer , b as integer ) '这里用于偷懒
Dim t as integer
a = t : a = b : b = t
End Function
Function Quicksort ( a () As integer , p As integer , q As integer )
'p为最左序号,q为最右序号,a为待排序数组
Dim r As integer , i As integer
If p >= q Then Exit Function
' 在只有一个数或没有数时 , 则认为已经排好 , 不必再排
r = p 'r作为临时变量,记录最左侧的位置
For i = p To q - 1 '遍历范围内的数
If a ( i ) < a ( q ) Then '以q处的数字为基准数
Swap a ( i ), a ( r ) '小于,就和r处(左侧)交换
r = r + 1 '把左侧的记录点右移,准备下一个数进来换
End if
Next i
Swap a ( q ), a ( r ) '将基准数放到r处,此时比基准数小的数都在其左侧了
Quicksort a () , p , r - 1 : Quicksort a () , r + 1 , q
'r的左右两边再分而治之,递归
End Function
Private Sub Command1_Click () '用于输出
Quicksort a (), 1 , 10 '1,10是所需排序数组的首个和末个序号
For i = 1 To 10
List1 . AddItem Str ( a ( i ))
Next i
End Sub
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
'归并排序
Const n = 10
Dim d ( 1 To n ) As Integer '全局变量,待排序数组
Private Sub Form_Load () '造随机数并输出
Randomize
For i = 1 To n
d ( i ) = Int ( Rnd * 100 ) + 1
List1 . AddItem Str ( d ( i ))
Next i
End Sub
Private Sub Command1_Click () '简单调用一下函数,输出
Call sort ( 1 , ( n + 1 ) \ 2 , ( n + 1 ) \ 2 + 1 , n )
For i = 1 To n
List2 . AddItem Str ( d ( i ))
Next i
End Sub
'下面才是重点内容
Sub sort ( first1 As Integer , last1 As Integer , first2 As Integer , last2 As Integer )
'参数: 前段段首编号 前段段末编号 后段段前编号 后段段末编号
Dim dt ( 1 To n ) As Integer '暂存输出数组
If first1 < last1 Then
Call sort ( first1 , ( first1 + last1 ) \ 2 , ( first1 + last1 ) \ 2 + 1 , last1 )
End If
If first2 < last2 Then
Call sort ( first2 , ( first2 + last2 ) \ 2 , ( first2 + last2 ) \ 2 + 1 , last2 )
End If
'分,不停调用自己,直到每一段只有1个数字长(第一步)
f1 = first1
f2 = first2
For i = first1 To last2
If f1 > last1 Then
dt ( i ) = d ( f2 )
f2 = f2 + 1
ElseIf f2 > last2 Then
dt ( i ) = d ( f1 )
f1 = f1 + 1
ElseIf d ( f1 ) < d ( f2 ) Then
dt ( i ) = d ( f1 )
f1 = f1 + 1
Else
dt ( i ) = d ( f2 )
f2 = f2 + 1
End If
Next i
For i = first1 To last2
d ( i ) = dt ( i ) '输出,后面将再被调用
Next i
End Sub
(爱来自高中,VB文艺复兴)
在实际工作中经常会遇到一个复杂的问题不能简单地分成几个子问题,而是会分解出一系列子问题。如果用分治法的话,可能会使得递归调用的次数呈指数增长,如斐波那契数列的计算。为了节约重复求相同子问题的时间,可引入一个数组。从最小规模开始计算问题的解。不管某个解对最终解是否有用,都把它保存在该数组中。在计算规模较大的问题需要用到规模较小的问题的解时,可以从数组中直接取出答案 ,这就是动态规划的基本思想。
如硬币找零问题,不用贪心算法的话(比如不是1,5,10,20的面值),可动态规划。即从小到大计算找零的方案。先生成0分钱的最优找零方案,再找出1分钱的最优找零方案,……,直到找到了63分钱的最优找零方案。在每次得到一个方案时,就把方案存储起来。当再次遇到这个子问题时就不用重复计算了。
(高中资料又一次复兴)
你小子现在才讲,劳资已经在前面自己查过了,见5.1.1“小插曲——const/constexpr”。
1
2
3
4
5
constexpr int f1 () { return 10 ;}
constexpr int x = 1 + f1 (); //这样可行
//我是分界线
int f1 () { return 10 ;}
constexpr int x = 1 + f1 (); //这样报错
定义常量表达式时出现了一个函数调用,虽然该函数的返回值是一个常量,但编译器不会检查函数调用的结果是否是编译时的常量。
constexpr函数中只能有一个return语句,且不允许有其他执行操作的语句,但可以有类型别名,空语句等。
编译时,编译器将函数调用替换成函数的返回值。因此,constexpr函数被隐式地指定为内联函数。
注意,constexpr函数的返回值可以不是常量。例如,当调用函数f2的实际参数是常量时,返回值是编译时的常量,当实际参数是变量时,返回值是非常量。当把constexpr函数用于常量表达式时,编译器会检查函数结果是否符合要求。如果不是常量,则会发出错误信息。
1
2
3
template < class Type1 , class Type2 >
auto cal ( Type1 alpha , Type2 beta ) -> decltype ( alpha + beta ) {
return alpha + beta ; }
使用函数模板时,有时候没法提前知道输出的类型。
在函数返回类型处,用auto表示由编译器自动推导。真正的类型由->后面的decltype(alpha +beta)决定。通过尾置返回类型,cal()的类型可以由编译器类型推导得出,提高了语言的方便性和安全性。
全局变量为函数间的信息交互提供了便利,但也破坏了函数的独立性。每个函数是一个独立的功能模块,尽量不要让一个函数影响另一个函数的执行结果。在程序中要慎用全局变量。
程序可以通过变量名访问这块空间中的数据。这种访问方式称为直接访问。
指针变量就是保存另一个变量地址的变量。指针变量存在的意义在于提供间接访问,即从一个变量访问到另一个变量的值,使变量访问更加灵活。
地址是内存的地址,单位是字节,注意是16进制。64位的电脑,一个指针占8字节,32位的则是4字节。
1
2
int * p , * q , r ; //pq是指向整型的指针,r是整型变量
char * s ; //s是指向字符型的指针
指针指向的变量的类型称为指针的基本类型 。
指针变量中保存的地址一定是同一个程序中的某个变量的地址,以后可以通过指针变量间接访问。因此,为指针赋值有两种方法:一种是将本程序的某一变量的地址赋给指针变量,另一种方法是将一指针变量的值赋给另一个指针变量。
取地址运算符&。&运算符是一个一元运算符,运算对象是一个变量,运算结果是该变量对应的内存地址。
1
2
int x , * p =& x , * q ; // 定义了整型变量x和指向整型的指针p,同时让p指向x。
q = p ; //把p指针地址赋值给q指针
在定义指针的时候,如果不用指针,则赋值NULL比较安全。因为访问一个随机的内存地址是危险的。
NULL是C++定义的一个符号常量,它的值为0,表示不指向任何地址。
在对指针进行赋值的时候必须注意,赋值号两边的指针类型必须相同。不同类型的指针之间不能赋值。道理很简单,如果p1是指向整型数的指针,而p2是指向double型的指针,执行p2=p1,然后引用p2指向的内容,会发生什么问题?由于p2是指向double型的指针,在Visual C++中引用p2指向的内存时就会取8字节的内容,然后把它解释成一个double型的数,而整型变量在Visual C++中只占4字节!即使两个指针类型不同,但指向的空间大小是一样的,这两个指针间的赋值还是没有意义的。如果p1是指向整型数的指针,而p2是指向float型的指针,执行p2 =p1,然后引用p2指向的内容,则会将一个整型数在内存中的表示解释成一个单精度数。这是没有意义的。因此,C++不允许不同类型的指针之间互相赋值。如果必须在不同类型的指针间相互赋值,必须使用强制类型转换,表示程序员知道该赋值的危险。
取指针指向的值的运算符*。*运算符是一元运算符,它的运算对象是一个指针。*运算符根据指针的类型,返回其指向的变量。而&用于取地址。
1
2
3
4
int x , y , * p ;
x = 3 ; y = 4 ; p =& x ;
* p = y + 1 ; // 这行的效果与x=y+1一样
p =& y ; * p = y + 1 ; // 这行将p指向y,后执行y=y+1
可以将指针的基本类型声明为void。void类型的指针只说明了这个变量中存放的是一个内存地址,但未说明该地址中存放的是什么类型的数据。只有相同类型的指针之间能互相赋值,但任何类型的指针都能与void类型的指针互相赋值,因此void类型的指针被称为统配指针类型。
为了防止通过指针随意修改变量的值,可以采用常量限定符const来限制通过指针修改它指向的地址中的内容。
const对左边生效,除非const在最左边。在最左边则对右边生效。
常量指针:指向的内容是常量的指针变量。常量指针只限制指针的间接访问,而指针本身的访问不受限制。
1
const int * p =& y // 由于p是指向整型常量的指针,不能通过p修改y的值。所以通过p进行间接访问是安全的,不会修改被访问单元的值。
指针常量:指针本身是个常量,它固定指向某一变量。因此它本身的值不能变,但它指向的地址中的值是可变的。
此时,*p值可以修改,但是p指向的地址不能修改
指向常量的指针常量:指针本身不能改变,指向的地址中的值也不能改变。
这样就都不能改了。
空指针常量nullptr
通常给不指向任何变量的指针赋一个特殊值NULL。引用指针时,最好先检查指针的值是否为NULL。NULL是一个C++预定义的符号常量,它的值是整数0。而这与函数重载配合时就会有问题。如有重载函数
1
2
void f ( int * );
void f ( int );
那么,f(NULL)将会调用函数f(int),而这肯定不是程序员的原意。
于是乎,我们应该写f(nullptr)来调用f(int*)
C++规定对指针只能执行加减运算。指针的加减是考虑了指针的基本类型。对指针变量p加1,p的值增加了一个基类型的长度。如果p是指向整型的指针,并且它的值为1000,在VC6.0中执行了++p后,它的值为1004。
对一个指向某个简单变量的指针执行加减运算是没有意义的。指针的运算是与数组有关。如果指针p指向数组arr的第k个元素,那么p+i指向第k+i个元素,p-i指向第k-i个元素。
数组名保存了数组的起始地址,也就是说数组名是一个指针常量。将一个数组名赋给一个指针后,该指针就具备了数组名的行为。
1
2
3
4
5
6
7
8
int intarray [ 5 ];
int * p = intarray ;
//下面五行都是一样的
for ( i = 0 ; i < 5 ; ++ i ) cout << intarray [ i ] ;
for ( i = 0 ; i < 5 ; ++ i ) cout << * ( intarray + i );
for ( p = intarray ; p < intarray + 5 ; ++ p ) cout << * p ;
for ( p = intarray , i = 0 ; i < 5 ; ++ i ) cout << * ( p + i );
for ( p = intarray , i = 0 ; i < 5 ; ++ i ) cout << p [ i ] ;
但是注意不能只定义了p就拿它当数组用,因为只定义p系统将不知道要分配一个数组的内存。
所谓动态变量是指:在写程序时无法确定它们的存在,只有当程序运行起来,随着程序的运行,根据程序的需求动态产生和消亡的变量。由于动态变量不能在程序中定义,也就无法给它们取名字,因此动态变量的访问需要通过指向动态变量的指针变量来进行间接访问。动态变量的空间需要程序员在程序中显式地释放。
1
2
3
4
5
6
7
new 类型名 ; //这个操作在内存中称为堆(heap)的区域申请一块能存放相应类型的数据的空间,操作的结果是这块空间的首地址。
int * p ; p = new int ; * p = 20 ; //动态产生一个变量的指针*p,存储的数据为20
int * p = new int ( 20 ); //这和上一行效果一样,也实现了赋初值
int * q ; q = new double ; //非法操作,因为new操作是有类型的
int * t ; t = new int [ 10 ]; // 也可以创建数组,且10可以填变量
//C++03动态数组不能为数组元素赋初值。C++11可以。
int * p = new int [ 5 ]{ 1 , 2 , 3 , 4 , 5 }; //如果给出的初值个数多于数组元素个数,则new操作失败。
动态数组只能用下标变量访问,不能用范围for访问。
在一个函数中创建了一个动态变量,在该函数返回后,该动态变量依然存在,仍然可以使用。
1
2
3
4
int * p = new int ( 10 );
delete p ; //回收一个动态变量
int * t = new int [ 10 ];
delete [] t ; //回收一个动态数组
一旦释放了内存区域,堆管理器重新收回这些区域。虽然指针仍然指向这个堆区域,但已不能再使用指针指向的这些区域。如果再间接访问这块空间将导致程序异常终止。
所谓的内存泄漏是用动态变量机制申请了一个动态变量,而后不再需要这个动态变量时没有delete;或者把一个动态变量的地址放入一个指针变量,而在此变量没有delete之前,又让指针指向另一个动态变量。这样原来那块空间就丢失了。堆管理器认为你在继续使用它们,而你却不知道它们在哪里。
如果你的程序要运行很长时间,而且存在内存泄漏,这样程序最终可能会耗尽所有内存,直至崩溃。
堆空间可能用完,此时new操作就会失败,故在new之前要检查一下是否成功。当new操作成功时,返回申请到的堆空间的一个地址。如果不成功,则返回一个空指针。怎么检查呢?查一下new int的返回值是不是非0就行。(0则表示不成功)
也可以利用assert宏直接退出程序。assert()宏定义在标准头文件cassert中。使用assert()时,给它一个参数,即一个表示断言为真的表达式,预处理器产生测试该断言的代码。如果断言不是真,则在发出一个错误消息后程序会终止。
1
2
3
4
5
#include <cassert>
......
p = new int ;
assert ( p != 0 ); // 如果p是0,则直接终止程序
* p = 20 ;
数组的规模可以根据用户需求而申请。
如果申请动态变量时给出初值,就可以使用auto推断所需分配的对象类型。
1
auto p = new auto ( 10 ); //会自动判断为int型
注意,不能申请auto类型的动态数组。
1
2
3
4
5
6
7
8
9
10
11
12
#include<iostream>
using namespace std ;
int main (){
char * s1 , * s2 ;
char ch [] = "ffff" ;
s1 = "abcde" ; // C风格,编译器会报一个warning
s2 = ch ;
char * s3 = new char [ 10 ]; //只有这个是动态的(数据存在“堆”里)
strcpy ( s3 , "ghi" );
cout << s1 << s2 << s3 ;
return 0 ;
} // 输出abcdeffffghi
函数的参数可以是指针。指针传递可以降低参数传递的代价,以及让主函数和被调用函数共享同一块内存空间。
1
2
3
4
5
6
void swap ( int * a , int * b ){
int c = * a ;
* a = * b ;
* b = c ;
} //交换a和b的值
swap ( & x , & y ) ; //这么调用
应用的一个例子:实现返回多个值。函数只能有一个返回值,由return语句返回,而一个一元二次方程有两个解,如何让函数返回两个解?答案是可以在主函数中为方程的解准备好空间,如定义两个变量x1和x2,把x1和x2的地址传给解方程的函数,解方程函数将方程的解存入指定的地址。
数组传递的本质是地址传递,也就是说,传arr[]进去实际上只是传了指向arr的指针进去。
1
void sort ( int p [], int n ); // void sort (int* p, int n); 也可以
比如这是一个排序函数,可以排序数组p,数组p有n个元素。如果需要排序一个有10个元素的数组a,可以调用sort(a,10)。如果要排序前一半元素,则可调用sort(a,5)。如果要排序后一半元素,则可调用sort(a+5,5)。
下面是一个例子,用分治法查找最大值,这样是$log_2n$次运算,好于一个个查过去。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
//分治法查找最大最小值
#include<iostream>
using namespace std ;
void minmax ( int a [], int n , int * minp , int * maxp );
int main (){
cout << "输入这组数最大可能的个数" << endl ;
int max ;
cin >> max ;
int * a = new int [ max + 1 ];
cout << "输入一组数,用空格隔开,以.结束" << endl ;
int tmp , k = 0 ;
char c ;
while (( cin >> tmp ). get ( c )){
a [ k ] = tmp ;
++ k ;
if ( k == max ) {
cout << "超出最大值" << endl ;
break ;
}
if ( c == '.' ) break ;
}
int mins , maxs ;
int * minp =& mins , * maxp =& maxs ;
cout << "有" << k << "个数" << endl ;
minmax ( a , k , minp , maxp );
cout << "最小=" <<* minp << " 最大=" <<* maxp << endl ;
delete [] a ;
return 0 ;
}
void minmax ( int a [], int n , int * minp , int * maxp ){
int min1 , max1 , min2 , max2 ;
switch ( n ){
case 1 : //如果数组中只有一个元素,那么最大最小值都是这个元素
* minp = a [ 0 ]; * maxp = a [ 0 ];
break ;
case 2 : //如果数组中只有两个元素,则大的一个就是最大值,小的那个就是最小值
if ( a [ 0 ] > a [ 1 ]) { * maxp = a [ 0 ]; * minp = a [ 1 ];}
else { * maxp = a [ 1 ]; * minp = a [ 0 ];}
break ;
default :
minmax ( a , n / 2 , & min1 , & max1 ); //在前半段找最大最小值
minmax ( a + n / 2 , n - n / 2 , & min2 , & max2 ); //在后半段找最大最小值
if ( min1 < min2 ){ * minp = min1 ;} else { * minp = min2 ;}
if ( max1 > max2 ){ * maxp = max1 ;} else { * maxp = max2 ;}
break ;
}
return ;
}
1
2
3
4
5
6
char * s3 = "abcd" ; //这个是常量字符串,存在数据段,没法改
char s4 [] = "efgh" ; //这个存在栈,可改
char * s2 = new char [ 10 ];
strcpy ( s2 , "sjtu" ); // 这个存在堆,可改
cout << s2 + 2 <<* ( s2 + 2 ) << endl ; //前一个会当作字符串输出来,后一个会输出一个字符
cout << s4 + 2 << s4 [ 2 ] << endl ; //也是前一个出字符串,后一个出字符
1
2
3
4
5
6
7
8
9
10
11
12
13
#include<iostream>
using namespace std ;
int main (){
char a [] = "sjtu" ;
int b [] = { 9 , 2 , 3 , 4 , 5 };
char * p = a ;
int * q = b ;
cout << sizeof ( a ) << ' ' << sizeof ( a [ 2 ]) << ' ' << sizeof ( * a ) << ' ' <<* a << ' ' << p << ' ' << ( void * ) p << endl ;
cout << sizeof ( b ) << ' ' << sizeof ( b [ 2 ]) << ' ' << sizeof ( * b ) << ' ' <<* b << ' ' << q << ' ' << ( void * ) q << endl ;
}
//输出
//5 1 1 s sjtu 0x7ffee6b9256b
//20 4 4 9 0x7ffee6b92570 0x7ffee6b92570
如果传递的是一个字符串,通常使用指向字符的指针。由于字符串有一个特定的结束标志'\0',因此与数组作为参数传递不同,传递一个字符串只需要一个参数,即指向字符串中第一个字符的指针,而不需要指出字符串的长度。传递一个字符串就是传递一个指向字符的指针,而该函数只是读这个字符串并不修改这个字符串,所以可以用const限定这个形式参数。
函数的返回值可以是一个指针。表示函数的返回值是一个指针只需在函数名前加一个*号。
值得注意的是,当函数的返回值是指针时,返回地址对应的变量可以是全局变量或动态变量,或调用程序中的某个局部变量,但不能是被调函数的局部变量。这是因为当被调函数返回后,局部变量已消失,当调用者通过函数返回的地址去访问地址中的内容时,会发现已无权使用该地址。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
//从一个字符串中取出一个子串
char * subString ( char * s , int start , int end )
{
int len = strlen ( s );
if ( start < 0 || start >= len || end < 0 || end >= len || start > end ) {
cout << "起始或终止位置错" << endl ;
return NULL ;
}
char * sub = new char [ end - start + 2 ]; // 为子串准备空间
//如果不准备空间,直接返回一个在函数中申请的变量的地址,外面的函数将访问不了,因为函数结束之后会把函数内申请的栈里的空间都释放掉
strncpy ( sub , s + start , end - start + 1 );
sub [ end - start + 1 ] = '\0' ;
return sub ;
}
引用类型,它也能通过一个变量访问另一个变量,而且比指针类型安全。所谓的引用就是给变量取一个别名,使一块内存空间可以通过几个变量名来访问。声明引用类型的变量需要在变量名前加上符号&,并且必须指定初值 ,即被引用的变量(不能在定义完成后再赋值)。
1
2
3
4
5
int i ;
int & j = i ; //当编译器遇到这个语句时,并不会为变量j分配空间,而只是把变量j和变量i的地址关联起来。
int & k = j ; //为引用提供的初始值可以是一个变量或另一个引用。
int a ;
const int & b = a ; //合法。但是如果想赋值,只能通过变量a。
引用实际上是一种隐式指针。但每次使用引用变量时,可以不用书写运算符“*”,因而简化了程序的书写。不过,引用与被引用变量之间的绑定是永久的,而指针可以通过赋值指向另一个变量。
1
2
3
4
int a [ 10 ] = { 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 };
for ( int k : a ) cout << k ; //范围for。该语句表示定义变量k,让它依次等于a的每个元素,执行循环体指定的操作。
for ( int k : a ) cin >> k ; //这不能达到目的。因为数据是输入给变量k,而不是数组a,尽管输入前k的值是数组某个元素的值。
for ( int & k : a ) cin >> k ; //这样能达到修改数组元素的目的。
1
2
3
4
5
6
7
8
void swap ( int & a , int & b ){ //调用时,相当于跑了一行int &a = x, &b = y;
int c ;
c = a ; a = b ; b = c ;
} //引用写法,更优雅
void swap ( int * a , int * b ){
int c ;
c =* a ; * a = * b ; * b = c ;
} //指针写法
引用传递可以减小函数调用的代价。系统不需要为引用传递的参数分配内存空间,也不需要复制实际参数的副本。如果不希望参数本身发生改变,可以用const引用。
1
2
int max ( const int & a , const int & b ); //const引用
//该形式参数在函数中充当的是常量的角色,不能被修改。
如果想传进来常量,则必须
函数的返回值也可以是引用类型,它表示函数的返回值是函数内某一个变量的引用。当函数返回值是引用类型时,不需要创建一个临时变量存放返回值,而是直接返回return后的变量本身。返回引用一方面可以提高效率,更重要的是可以将函数调用作为赋值运算符的左运算数,即将函数调用作为左值 。
确保引用返回是正确的最好方法就是问一下自己,返回的这个变量在函数执行结束后是否存在。(比如返回一个函数的局部变量,则不行,因为函数运行完这个变量就被销毁了。另外,也不能返回一个表达式。)
1
2
3
4
5
6
7
8
9
10
//返回引用值的函数示例
#include <iostream>
using namespace std ;
int a [] = { 1 , 3 , 5 , 7 , 9 };
int & index ( int ); //声明返回引用的函数
void main (){
index ( 2 ) = 25 ; //将a[2]重新赋值为25
cout << index ( 2 );
}
int & index ( int j ){ return a [ j ]; }
不能建立引用数组;
不能建指向引用的指针 int & * p=q ; 不行;
可以有指向指针的引用 int * & p=q ; 行;
不能建立引用的引用。
左值是指表达式结束后依然存在的持久对象,在内存有一块固定的存储空间,因而可以放在赋值号的左边。右值是指表达式结束后就不再存在的临时对象,该对象被使用后就消亡了。
C++11中支持右值引用,以&&表示。
1
2
3
char * city [ 12 ] = { "Atlanta" , "Boston" , "Chicago" , "Denver" , "Detroit" ,
"Hoston" , "Los Angeles" , "Miami" , "New York" ,
"Philadelphia" , "San Francisco" , "Seattle”};
数组的每个元素都是指针,用来做什么呢?比如用来存一组字符串。
也可以用来申请动态的二维数组。
1
2
3
4
5
6
7
8
9
int n ; cin >> n ;
ll * * map = new ll * [ n + 1 ];
for ( int i = 0 ; i < n + 1 ; ++ i ){
map [ i ] = new ll [ n + 1 ];
} //下面就可以用map[i][j]了
for ( int i = 0 ; i < n + 1 ; ++ i ){
delete [] map [ i ];
}
delete [] map ; //记得释放内存
main函数可以有两个形式参数:第一个形式参数习惯上称为argc,是一个整型参数,它的值是运行程序时命令行中的参数个数;第二个形式参数习惯上称为argv,是一个指向字符的指针数组,它的每个元素是指向一个实际参数的指针。每个实际参数都表示为一个字符串。argc也可看成是数组argv的元素个数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
//带参数的main函数示例
#include <iostream>
using namespace std ;
int main ( int argc , char * argv []){ //只能是这两个数据类型,比如int不能改成long。不过argc和argv的名字可以改。
int i ;
cout << "argc=" << argc << endl ;
for ( i = 0 ; i < argc ; ++ i )
cout << "argv[" << i << "]=" << argv [ i ] << endl ;
return 0 ;
}
//注意:打开这个程序本身写的那条命令也会被算入argc和argv中。比如,如果这个文件叫做test,我们已经在它所在的文件夹,在命令行输入./test something1 something2则会输出
// argc=3
// argv[0]=./test
// argv[1]=something1
// argv[2]=something2
注意,对于读入数字的情况,argv仍旧会把它当作字符串存进去。
指向指针的指针……套娃也。只需加*即可。
见7.7.1
在C++中,指针可以指向一个整型变量、实型变量、字符串、数组等,也可以指向一个函数。所谓指针指向一个函数就是让指针保存这个函数的入口地址,以后就可以通过这个指针调用某一个函数。这样的指针称为指向函数的指针 。
1
2
3
4
5
6
返回类型 ( * 指针变量 )( 形式参数表 );
int ( * p1 )( int , int );
指针变量名 = 函数名 ;
int f1 ( int , int );
p1 = f1 ; // 写成p1=&f1是一样的。
//调用时 p1() (*p1)() f1() 等价
注意,指针变量外的圆括号不能省略。如果没有这对圆括号,编译器会认为声明了一个返回指针值的函数。
另外,在为指向函数的指针赋值中,所赋的值必须是与指向函数的指针的原型完全一样的函数名。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
#include<iostream>
using namespace std ;
bool increase ( int x , int y ) { return x < y ;}
bool decrease ( int x , int y ) { return y < x ;}
bool increase ( char * x , char * y ) { return strcmp ( x , y ) < 0 ;}
bool decrease ( char * x , char * y ) { return strcmp ( x , y ) > 0 ;}
//重载函数方便地解决类型问题
template < class T > //函数模板
void sort ( T a [], int size , bool ( * f )( T , T )){
//bool (*f)(T,T)是指传入一个函数指针,这个函数用来比较T类型和T类型之间的大小
//亲测没有*也能跑
bool flag ;
for ( int i = 1 ; i < size ; ++ i ){ //冒泡排序
flag = false ;
for ( int j = 0 ; j < size - i ; ++ j ){
if ( f ( a [ j + 1 ], a [ j ])){
T tmp = a [ j ]; a [ j ] = a [ j + 1 ]; a [ j + 1 ] = tmp ; //注意这里要用T类型来定义tmp
flag = true ;
}
}
if ( ! flag ) break ;
}
}
int main (){
int a [] = { 3 , 1 , 4 , 2 , 5 , 8 , 6 , 7 , 0 , 9 }, i ;
char * b [] = { "aaa" , "bbb" , "fff" , "ttt" , "hhh" , "ddd" , "ggg" , "www" , "rrr" , "vvv" };
sort ( a , 10 , increase );
for ( i = 0 ; i < 10 ; ++ i ) cout << a [ i ] << " \t " ;
cout << endl ;
sort ( a , 10 , decrease );
for ( i = 0 ; i < 10 ; ++ i ) cout << a [ i ] << " \t " ;
cout << endl ;
sort ( b , 10 , increase );
for ( i = 0 ; i < 10 ; ++ i ) cout << b [ i ] << " \t " ;
cout << endl ;
sort ( b , 10 , decrease );
for ( i = 0 ; i < 10 ; ++ i ) cout << b [ i ] << " \t " ;
cout << endl ;
return 0 ;
} //输出如下
// 0 1 2 3 4 5 6 7 8 9
// 9 8 7 6 5 4 3 2 1 0
// aaa bbb ddd fff ggg hhh rrr ttt vvv www
// www vvv ttt rrr hhh ggg fff ddd bbb aaa
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
//文件名:7-18.cpp
//用函数指针实现菜单选择
int main (){
int select ;
void ( * func [ 5 ])() = { NULL , add , erase , modify , print }; //定义一个指向函数的数组
while ( 1 ) {
cout << "1--add \n " ;
cout << "2--delete \n " ;
cout << "3--modify \n " ;
cout << "4--print \n " ;
cout << "0--quit \n " ;
cin >> select ;
if ( select == 0 ) return 0 ;
if ( select > 5 ) cout << "input error \n " ; else func [ select ]();
}
}
捕获列表是一个lambda表达式所在的函数中定义的局部变量列表,返回类型、参数表和函数体与普通函数相同。但是与普通函数不同,lambda函数必须使用尾置返回类型。
1
2
3
4
5
6
7
8
[ 捕获列表 ]( 参数表 ) -> 返回类型 { 函数体 }
[]( int x , int y ) -> int { int z = x + y ; return z ; }
//这是一个合法的lambda函数
[]( int x , int y ) { return x + y ; }
[]( int & x ) { ++ x ; }
//没有return语句或只有一个return语句,而且返回类型很明确时,lambda函数可以不指定返回类型。
auto f = []( int x , int y ) { return x + y ; };
//可以赋值给一个函数指针,以后可以通过函数指针调用该函数。可通过f(3,6)调用该lambda函数,得结果9。
捕获的方式:
空白 --不捕获参数;
x --用值捕获方式捕获变量x;
= --以值捕获方式捕获所有变量;
&x --以引用捕获方式捕获变量x;
& --以引用捕获方式捕获所有变量。
如果是值捕获,会创建一个临时变量。但要注意,临时变量是在lambda创建时拷贝,而不是在调用时拷贝。
7.8.2中的函数有着更优雅的实现方式如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
#include <iostream>
#include <cstring>
using namespace std ;
template < class T > //函数模板
void sort ( T a [], int size , bool ( * f )( T , T )){
//bool (*f)(T,T)是指传入一个函数指针,这个函数用来比较T类型和T类型之间的大小
bool flag ;
for ( int i = 1 ; i < size ; ++ i ){ //冒泡排序
flag = false ;
for ( int j = 0 ; j < size - i ; ++ j ){
if ( f ( a [ j + 1 ], a [ j ])){
T tmp = a [ j ]; a [ j ] = a [ j + 1 ]; a [ j + 1 ] = tmp ; //注意这里要用T类型来定义tmp
flag = true ;
}
}
if ( ! flag ) break ;
}
}
int main (){
int a [] = { 3 , 1 , 4 , 2 , 5 , 8 , 6 , 7 , 0 , 9 }, i ;
char * b [] = { "aaa" , "bbb" , "fff" , "ttt" , "hhh" , "ddd" , "ggg" , "www" , "rrr" , "vvv" };
sort < int > ( a , 10 , []( int x , int y ) -> bool { return x > y ; });
for ( i = 0 ; i < 10 ; ++ i ) cout << a [ i ] << " \t " ;
cout << endl ;
sort < int > ( a , 10 , []( int x , int y ) -> bool { return x < y ; });
for ( i = 0 ; i < 10 ; ++ i ) cout << a [ i ] << " \t " ;
cout << endl ;
sort < char *> ( b , 10 , []( char * x , char * y ) -> bool { return strcmp ( x , y ) > 0 ; });
for ( i = 0 ; i < 10 ; ++ i ) cout << b [ i ] << " \t " ;
cout << endl ;
sort < char *> ( b , 10 , []( char * x , char * y ) -> bool { return strcmp ( x , y ) < 0 ; });
for ( i = 0 ; i < 10 ; ++ i ) cout << b [ i ] << " \t " ;
cout << endl ;
return 0 ;
}
在指针使用中的一个较常见的错误是在不同类型的指针之间互相赋值,以及间接访问一个未赋值的指针。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
#include<iostream>
using namespace std ;
int main (){
int arr [ 5 ] = { 1 , 2 , 3 , 4 , 5 };
cout <<* arr << endl ;
cout <<* ( arr + 1 ) << endl ;
cout <<* (( int * )( & arr + 1 )) << endl ;
cout <<* (( int * )( & arr + 1 ) - 1 ) << endl ;
//第三行输出中,首先得到了指向整个数组的指针,对其进行加一操作,指针就指向了整个数组后面的地址,也就是5后面的地址,那么此时将其转化为int*类型再输出,就得到了该未初始化过的值。
//第四行输出中,过程为,指针指向5后面的地址,转为int*类型,此时的减一操作使指针移动一个int类型大小的地址空间,那么便指向了5。
// 1
// 2
// 32766
// 5
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
#include<iostream>
using namespace std ;
int main (){
int i = 42 ;
double o =- 3.92 ;
const int & q = i ;
//正常用法
const int & r = 12 ;
const int & s = q * 2 ;
const double & w = i ;
const int & a = o ;
//上面这些会创建一个临时变量绑上去,double转int不论正负直接抛弃小数点
//int &d=o;
//不能绑不同类型的变量
//int &d=i*2;
//不能绑一个式子
int z = 2 , zz = 3 ;
const int * p1 =& z ;
//*p1=3; 不能修改
p1 =& zz ;
int const * p2 =& z ;
//*p2=1; 不能修改
p2 =& zz ;
int * const p3 =& z ;
* p3 = 1 ;
//p3=&zz; 不能修改
const int * const p4 =& z ;
//*p4=3;
//p4=&zz;
const int const * p5 =& z ;
//*p5=3;
p5 =& zz ; //可以运行,因为后面一个const没有对*生效,这不是指针常量
//duplicate 'const' declaration specifier
const int k = 3 , kk = 33 ;
//int &b=k;
//binding reference of type 'int' to value of type 'const int' drops 'const' qualifier
//非常量可以常量引用,但是常量不能用非常量引用
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
#include<iostream>
using namespace std ;
void www ( int b [][ 3 ]){
cout << b [ 1 ][ 2 ];
}
//数组就是数组,这样可以正常输出6
// void www(int **b){
// cout<<*(b+4);
// }
//报错. 数组不是指针,编译器尝试了类型转换但是报错了
//candidate function not viable: no known conversion from 'int [2][3]' to 'int **' for 1st argument
// void www(int *b[3]){
// cout<<b[1][2];
// }
//一样报错. int *b[3]是一个指针数组,它有3个元素,每个元素都是一个指向整数的指针
//candidate function not viable: no known conversion from 'int [2][3]' to 'int **' for 1st argument
void www1 ( int ( * b )[ 3 ]){
cout << b [ 1 ][ 2 ];
}
//这个能跑
//int (*b)[3]是一个指向包含3个整数的数组的指针,指向数组的指针和指向指针的指针是不一样的
void rrr ( int * b ){
cout << b [ 2 ];
}
//对于一维数组,能发生自动类型转换,然后正常输出6
void qqq ( int & b ){
cout << b ;
}
//这是传入一个数,当然没有问题
// void sss(int* &b){
// cout<<b[2];
// }
//函数rrr可以运行,但是函数sss不行,为什么不能用引用?
//candidate function not viable: no known conversion from 'int [3]' to 'int *&' for 1st argument
int main (){
int b [ 2 ][ 3 ] = {{ 1 , 2 , 3 },{ 4 , 5 , 6 }};
www ( b );
www1 ( b );
rrr ( b [ 1 ]);
qqq ( b [ 1 ][ 2 ]);
// sss(b[1]);
}
//6666
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
#include <iostream>
using namespace std ;
int main ()
{
int arr [ 3 ][ 4 ] = {{ 1 , 2 , 3 , 4 },{ 5 , 6 , 7 , 8 },{ 9 , 10 , 11 , 12 }};
int ( * p )[ 4 ] = arr ;
cout <<& arr << ' ' << arr << endl ;
cout <<* p << ' ' << p << endl ;
cout << sizeof ( arr ) << ' ' << sizeof ( p ) << endl ;
cout <<* ( * p + 1 ) << ' ' <<* ( * ( p + 1 )) << endl ;
return 0 ;
}
//0x7ffee7815550 0x7ffee7815550
//0x7ffee7815550 0x7ffee7815550
//48 8
//2 5
注意点运算符的优先级比*运算符高,(*sp).ss和sp->ss都可以
结构体作为函数的参数,用引用传递减少内存消耗,用常量引用传递保护值不被修改
结构体直接当参数,默认值传递,浪费空间。(数组的默认是地址传递)
函数也可以返回结构体
结构体的sizeof是里面所有东西的大小,但是注意内存对齐4字节,函数声明不占大小。
函数声明后,外面定义记得用 “返回类型 结构体名::函数名(形式参数表)”,调用成员函数还是用点就可以
头文件是直接被复制上去的,里面干了什么要想清楚了!(比如定义全局变量,直接报错)
此外,两个.cpp才是主要,我们用g++ -o。
函数放入结构体->类
类缺省访问控制是private。用public:使类外成员可以调用。
直接定义在类中的函数默认为内联函数,如果现在实现(.h外的.cpp)中则可以手动inline来内联。
隐藏的形参*this ,表示类自己。如果要把类自己当作整体拿出来用,显式地用*this
同类对象可以赋值,直接逐位复制
构造函数、析构函数~:没有返回类型, 名字是类名,构造函数可以重载来满足不同需求,可以加默认值。
复制构造函数: 类名(const 类名 &) 构造函数的一种,参数是自己这个类的常量引用。 自动生成的复制构造函数可能不完全满足需求,比如需要new一块空间,但是直接复制只是抄了一个指针。三种场合,对象定义时、函数调用时、函数返回时(不一定),会调用复制构造函数。
遇到变量定义时调用构造函数,局部变量先消失,然后静态,再全局,后创建的先消失。
类的嵌套需要初始化列表,类有嵌套时,需先初始化内部的类,内部的类要先搞好构造函数
下面是两个简单实例。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
//静态成员介绍
class A {
public :
static int a ;
static void set ( int aa ){
a = aa ;
}
};
int A :: a = 0 ;
int main (){
A :: set ( 3 ); //在没有实例的时候就可以对静态数据成员进行操作
A q ;
q . a = 1 ;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
//一个全面的例子
#include<iostream>
using namespace std ;
class Test {
int a ; const int b ;
public :
Test ( int aa , int bb );
void si ();
void add ( int d ){
a += d ;
}
void put () const { //常量成员函数
cout << a ;
}
int aaa () const {
return a ;
}
};
Test :: Test ( int aa , int bb ) : b ( bb ){
a = aa ;
}
void Test :: si (){
cout << b ;
}
class MyTest {
friend void ff ( const MyTest & x ); //声明友元函数,定义在外面全局.注意友元不传递,不对称.
private :
int k ;
//static int q=2;
//non-const static data member must be initialized out of line
static int q ; //静态数据成员必须在外面初始化,静态数据成员是所有这个类的实例共享的
static const int c = 31 ; //静态常量数据成员直接在里面赋值,各个实例共享
const int w ; //常量数据成员,用构造函数初始化,各个实例各自有各自的
public :
Test test ;
MyTest ( int a , int b , int c , int d );
void put (){
cout << q << ' ' << w << endl ;
}
static void set ( int s ){ //静态成员函数
q = s ;
//k++; 静态成员函数没有this指针,只能修改静态数据成员
}
};
int MyTest :: q = 2 ;
// void MyTest::set(int s){
// q=s;
// } 也可以在外面定义静态函数成员,里面只声明.在外面定义时外面不写static.
MyTest :: MyTest ( int a , int b , int c , int d = 9 ) : test ( a , b ), w ( d ){
k = c ;
}
void ff ( const MyTest & x ){
cout << "friend " << x . test . aaa () << endl ;
}
int main (){
MyTest aaa ( 2 , 3 , 4 );
aaa . test . put ();
aaa . test . add ( 6 );
aaa . test . put ();
aaa . test . si ();
const MyTest bbb ( 5 , 6 , 7 );
//bbb.test.si(); 定义为常量的类对象只能调用常量函数
bbb . test . put ();
cout << endl ;
aaa . put ();
aaa . set ( 9 ); //调用静态函数
aaa . put ();
MyTest :: set ( 7 ); //也可以这样调用静态函数
aaa . put ();
ff ( aaa );
}
上面那个例子中就用到了组合
组合:新类的成员是旧类 (新类 has 旧类)
继承:新类是旧类的特殊实例(新类 is 旧类)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
#include<iostream>
using namespace std ;
class Base {
int x ;
public :
static int s ;
Base ( int a ) : x ( a ){}
void setx ( int k ){
x = k ;
}
int & getx (){
return x ;
}
void prt (){
cout << x ;
}
virtual int ss () { return 0 ;} //虚函数
};
int Base :: s = 4 ;
class Derived1 : public Base { //派生类名:继承方式 基类名
int y ;
public :
Derived1 ( int a , int b ) : Base ( a ), y ( b ){}
void sety ( int k ){
y = k ;
}
void prt (){
cout << getx () << '-' << y ; //重定义基类的成员函数,如果还想用基类的,则在函数名前加基类名的限定,像下面这样
// Base::prt(); cout<<' '<<y;
}
int ss () { return getx () * y ;} //重新定义虚函数,原型必须一模一样,差个const都不行
};
int main (){
Derived1 a ( 2 , 3 );
Base b ( 9 );
cout << b . s ;
cout << a . s ;
b = a ; //隐式地把派生类转换为基类
b . prt ();
Base * p =& a ; //指针的类型决定了这个东西的行为,此时亦是基类,派生部分丢失
p -> prt ();
cout << p -> ss (); //但是对于虚函数就将出现多态
a . prt ();
cout << a . ss ();
}
基类
public继承
protected继承
private继承
public
Public
Protected
Private
protected
Protected
Protected
Private
private
不可访问
不可访问
不可访问
protected就是说对于子和友是public,对于其他人是private。
构造时,先建立基类,再建立派生类;析构时,先拆派生类,再拆基类。派生类析构,只负责析构新出的部分。
析构函数可以是虚函数,且最好是虚函数。派生类的析构函数执行时会自动调用基类的析构函数。
纯虚函数, virtual 返回类型 函数名(参数表)=0; 这样的话,派生类中必须要有自己的定义。
一个类至少有一个纯虚函数则被称为抽象类。抽象类不能建立实例,但是可以有指向派生类的指针和引用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
#include<iostream>
#include<fstream>
int main (){
ofstream out ( "file" );
ifstream in ;
if ( ! out ){ cerr << "error \n " ; return 1 ;}
int i = 2 ;
out . write ( reinterpret_cast < char *> ( & i ). sizeof ( int ));
out . close ();
in . open ( "file" );
if ( ! in . eof ()){
in . read ( reinterpret_cast < char *> ( & i ). sizeof ( int ));
}
}
Setw, setpercision,setbase...
 像这样。
像这样。